An Analysis of Scale Invariance in Object Detection – SNIP
动机
概括而言,这篇文章从COCO数据集开始分析,认为目前目标检测算法的难点在于数据集中object的尺寸分布较大,尤其对于小目标的检测效果也有待提高,因此提出Scale Normalization for Image Pyramids (SNIP)算法来解决这个问题。
作者将数据集按照图像中目标的尺寸/图像尺寸进行排序,在ImageNet数据集中,这个倍数的中位数差不多0.554,而在COCO数据集中,这个数是0.106。如Figure1中两条线标出的Median点所示。Figure1是关于ImageNet和COCO数据集中object尺寸和图像尺寸的倍数关系曲线,横坐标表示object的尺寸/图像尺寸的值,纵坐标表示占比。也就是说在COCO数据集中,大部分的object面积只有图像面积的1%以下,这说明在COCO数据集中小目标占比要比ImageNet数据集大。另外,从Figure1中的COCO曲线可以看出,第90%的倍数(0.472)差不多是第10%的倍数(0.106)的20倍!这说明在COCO数据集中的object尺寸变化范围非常大。
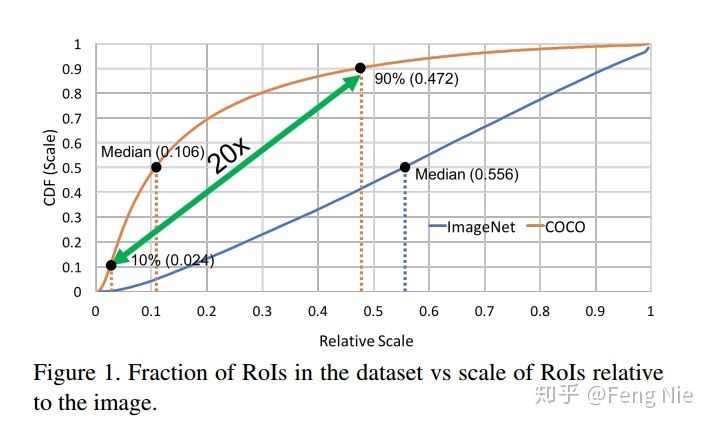
那么这种差异会带来什么影响呢?因为在目标检测算法中常用基于ImageNet数据集预训练的模型来提取特征,也就是常说的迁移学习,但是从Figure1的两条曲线可以看出ImageNet和COCO数据集在object的尺寸分布上差异比较大,这样在做迁移学习时可能会存在一些问题,文章中将这个问题概括为domain-shift,可以简单理解为训练集和测试集分布存在较大差异,后面会有实验来证明这种差异对效果的影响。其实YOLO v2也研究了类似的问题,YOLO v2考虑到在ImageNet数据集上预训练模型时输入图像大小是224x224,和检测网络用的尺寸差别较大(YOLO v2中常用416x416),所以就将预训练模型在416x416的ImageNet数据集上继续预训练,然后再用到检测模型提特征,这样就实现了预训练模型和检测模型的良好过渡。(所以,我们在Imagnet上做预训练,然后进行迁移学习时可能会存在一些问题,简单理解为训练集和测试集分布存在较大差异。)
其实之前就有不少算法针对数据集中不同尺寸的object检测进行改进,比如以Feature Pyramid Network(FPN)为例的通过融合高低层特征并基于多层融合特征单独预测的算法;以Dilated/Deformable Convolution为例的通过改变卷积核的感受野来提升检测效果;以multi-scale training/inference为例的通过引入图像金字塔来训练或验证图像。这篇文章基于对数据集的分析,提出一种新的训练模型的方式:Scale Normalization for Image Pyramids (SNIP),该算法主要包含两个改进点:
1、为了减少前面所提到的domain-shift,在梯度回传时只将和预训练模型所基于的训练数据尺寸相对应的ROI的梯度进行回传。
2、借鉴了multi-scale training的思想,引入图像金字塔来处理数据集中不同尺寸的数据。
几组实验
①ImageNet数据集实验验证尺寸变化对网络产生的影响

CNN-B:预训练:ImageNet数据集常规的224x224大小来训练
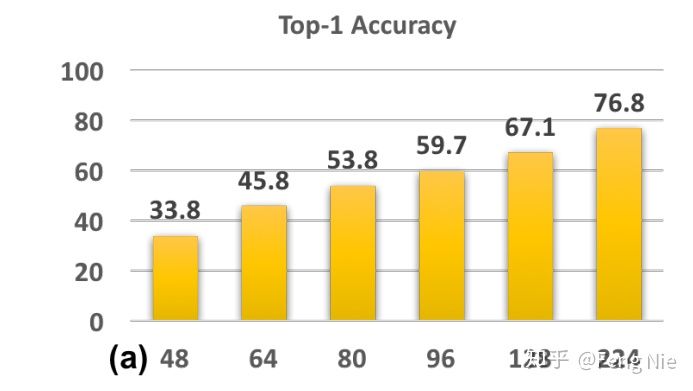
验证集:首先将ImageNet的验证数据缩小到48x48、64x64、80x80、96x96和128x128,然后再将这些尺寸放大到224x224作为模型的输入,可以看出放大后的图像分辨率较低。因此这个实验模拟的就是你训练数据的分辨率(resolution)和验证数据的分辨率不一致(甚至是差别很大)的时候对效果的影响,该实验的结果可以看Figure4(a)。
CNN-S:训练数据的分辨率和验证数据的分辨率保持一致,这里主要针对48x48和96x96分辨率,同时对网络结构的第一层做了修改。比如基于48x48的数据进行训练,将卷积核大小为7x7的卷积层换成卷积核为3x3,stride为1的卷积层(因为如果不修改stride的话很容易就卷没了)。基于96x96的数据进行训练时,将卷积核大小为7x7的卷积层换成卷积核尺寸为5x5,stride为2的卷积层。显然,该实验模拟的是训练数据分辨率和验证数据分辨率一致时的效果,实验结果可以看Figure4(b)(c)。
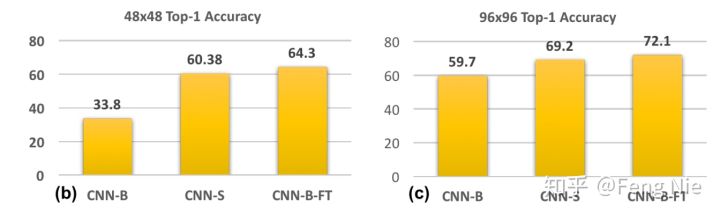
CNN-B-FT:是CNN-B在放大的低分辨率图像上微调后的模型,同时输入图像也采用放大的低分辨率图像。可以看出该实验主要验证基于高分辨率图像训练的模型是否能有效提取低分辨率图像的特征,实验结果可以看Figure4(b)(c)。
从(a)可以看出如果验证数据的分辨率和训练数据的分辨率差别越大,则实验结果越差。这说明其实CNN网络对尺寸变化的输入图像的鲁棒性(robust)还不够好。从(b)和(c)中CNN-B和CNN-S的对比可以看出当训练数据的分辨率和验证数据的分辨率相同时,效果要好很多。从(b)和(c)中CNN-B和CNN-B-FT的对比可以看出后者的效果要更好,二者的差别仅仅在于模型是否在放大的低分辨率图像上做fine tune,因此可以得出结论:基于高分辨率图像训练的模型同样能有效提取放大的低分辨率图像的特征。
②COCO数据集上关于多尺度和不同尺寸的训练对于实验结果的影响
Table1是关于在小目标验证集上的检测效果对比,所用的验证图像尺寸都是1400x2000。

800all和1400all:分别表示检测网络基于800x1400和1400x2000大小的图像进行训练,从二者的mAP结果对比可以看出1400all的效果要更好一些,主要原因就在于训练图像的分辨率和验证图像的分辨率一致,这和前面基于ImageNet数据集的实验结果也吻合,但这个提升非常小,猜测原因在于虽然基于放大图像(原始图像大概640x480,放大成1400x2000)训练的模型在训练过程中可以提高对小目标物体的检测,但是由于训练数据中尺寸中等或较大的目标的尺寸太大所以难以训练,这就影响了模型最终的效果。检测结果可以参考Figure5(1)。
1400<80px:表示训练数据尺寸是1400x2000,但是训练过程中忽略中等尺寸和大尺寸的目标(中等和大尺寸目标的标准是在原始图像中目标宽高的像素点大于80),也就是基于单一尺寸范围(scale-specific detector)的输入进行训练,目的是减少迁移误差。因此做这个实验的目的是基于前面那个实验中的猜想:基于1400x2000大小的图像训练时由于训练数据中尺寸中等及较大的目标对模型训练有负作用,因此这里直接在训练过程中忽略这样的数据。但是从Table1可以看出这个模型的效果非常差,猜想原因是忽略这些训练数据(占比大约30%)所带来的数据损失对模型效果的影响更大。具体的检测结果可以参考Figure5(2)。
Multi-Scale Training(MST):表示训练一个检测器时采用不同尺度的图像进行训练(包括480x800),也就是前面所说的scale invariant detector。照理来说这个实验的效果应该会比较好的,因为每个object都会有多种尺寸来训检测模型,但是从Table1可以看出该模型的效果和800all差不多,这是为什么呢?主要原因在于训练数据中那些尺寸非常大或非常小的object会影响训练效果。
Scale Normalization for Image Pyramids(SNIP)是这篇文章提出的算法,在引入MST思想的同时限定了不同尺寸的object在训练过程中的梯度回传,这就是SNIP。 从Table1可以看出效果提升非常明显。

Figure5是关于Table1中不同实验的训练数据展示。
SNIP
这篇文章基于对数据集的分析,提出一种新的训练模型的方式:Scale Normalization for Image Pyramids (SNIP),该算法主要包含两个改进点:
1、为了减少前面所提到的domain-shift,在梯度回传时只将和预训练模型所基于的训练数据尺寸相对应的ROI的梯度进行回传。
2、借鉴了multi-scale training的思想,引入图像金字塔来处理数据集中不同尺寸的数据。
从前面的分析可以看出,我们希望有一个算法能够既get到多尺度的目标信息,又能减少迁移误差带来的影响,因此就诞生了SNIP。SNIP借鉴了Multi-Scale Training(MST)的思想,在MST方法中,由于训练数据中尺寸极大或极小的目标会影响实验结果,因此SNIP的做法就是只对尺寸在指定范围内的目标回传损失(该范围需接近预训练模型的训练数据尺寸),也就是说训练过程实际上只是针对这些目标进行的,这样就能减少迁移误差带来的影响。又因为训练过程采用了类似MST的做法,所以每个目标在训练时都会有几个不同的尺寸,那么总有一个尺寸在指定的尺寸范围内。需要注意的是对目标的尺寸做限制是在训练过程,而不是预先对训练数据做过滤,训练数据还是基于所有数据进行
Figure6是SNIP算法的示意图。不管是训练检测器还是RPN网络,都是基于所有ground truth来定义proposal和anchor的标签。正如前面所述,某个ROI在某次训练中是否回传梯度是和预训练模型的数据尺寸相关的,也就是说当某个ROI的面积在指定范围内时,该ROI就是valid,也就是会在此次训练中回传梯度,否则就是无效的(如Figure6中右边的紫色框所示)。
其实就是先选择几个尺寸下相似的目标尺寸——>然后选定这些目标去回传梯度——>这些无效的ROI所对应的invalid ground truth会用来决定RPN网络中先验框——>无效先验框的定义是和invalid ground truth的IOU大于0.3的anchor。所以如图所示三个不同尺度下检测的目标大小近似,有效防止了过大或者过小目标对训练的影响。
即:
- 每个pipe-line的RPN只负责一个scale range的proposal生成。
- 对于大size的feature map,对应的RPN只负责预测被放大的小物体;对于小size的feature map,对应的RPN只负责预测被缩小的大物体;这样的设计保证了每个CNN分支在判别proposal是否为前景时,只需针对最易分类的中等range的proposal进行训练。
- 在Image Pyramid的基础上加入了 每层scale 的 proposal有效生成范围,发扬本scale的优势,回避其他scale的劣势,大大降低了前景分类任务的难度,从而“作弊式”地实现了Scale Invariance。

关于RPN网络中不同标签的anchor比例作者也做了分析,我们知道在RPN网络中,一个anchor的标签是根据该anchor和ground truth的IOU来决定的,只有两种情况下才会认为某个anchor的标签是正样本(标签为1):
1、假如该anchor和某个ground truth的IOU超过某个阈值(阈值默认采用是0.7),那么该ancho就是正样本。
2、假如一个ground truth和所有anchor的IOU都没超过该阈值,那么和该ground truth的IOU最大的那个anchor就是正样本。
同样,作者将conv4的输出作为RPN网络的输入,然后设置了15种anchor(5 scales,3 aspect ratios),接下来就有意思了,作者发现在COCO数据集上(图像大小为800 x 1200),只有30%的ground truth满足前面第一种情况!即便将阈值调整为0.5,也只有58%的ground truth满足第一种情况!这说明什么?
说明即便阈值等于0.5,仍有40%的正样本anchor和ground truth的IOU小于0.5(这些anchor是因为满足前面的情况2才被定义为正样本)!显然,这样的正样本质量不算很高。而这篇文章因为引入多种分辨率的图像作为输入,所以在一定程度上缓解了这种现象。另外,作者也尝试将conv4和conv5的特征做融合并预测,不过这部分文章只是一笔带过,还需要看源码才能知道具体是怎么做的。
实验结论
Table2是SNIP算法和其他算法的对比。第二行的multi-scale test显然比第一行的single scale效果要好。第三行,在multi-scale test的基础上加入multi-scale train的时候,会发现在大尺寸目标(APL)的检测效果上要比只有multi-scale test的时候差。这个原因我们在前面也介绍过了,主要是因为训练数据中那些尺寸极大和极小的object对训练产生了负作用。

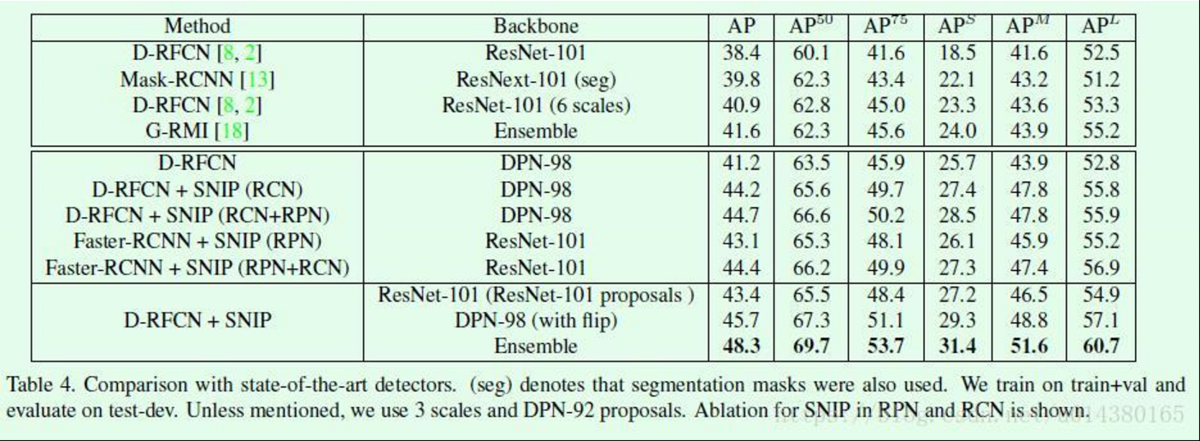
Table4是几个目标检测算法结果的对比。D-RFCN表示Deformable RFCN。D-RFCN+SNIP(RCN+RPN)表示在Deformable RFCN算法的检测模块和RPN网络中同时加入SNIP。