目标检测算法优化技巧
简介
目标检测模型相比于分类模型的研究相比,更缺少普遍性,并且网络结构和优化目标更加复杂。
本文主要是基于Faster R-CNN和YOLOv3来探索目标检测网络的调整策略。这些策略不会改变模型的结构,也不会引入额外的计算代价。通过使用这些trick,可以比SOTA提高最多5个百分点。
19年由亚马逊团队发表的《Bag of Freebies for Training Object Detection Neural Networks》。在使用了trick后,Faster R-CNN能提高1-2个百分点,而YOLOv3则提高了5个百分点。
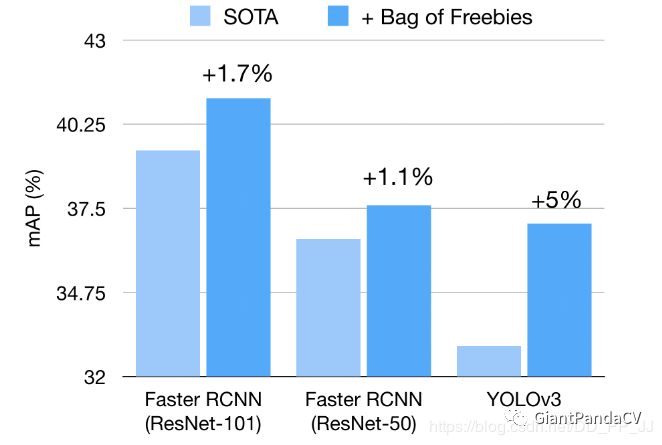
Trick
mixup
mixup也是图片分类中的一个非常有效的trick, 具体流程如下图所示:

简单来讲就是将两张图片通过不同的比例进行融合,同时图片对应的one-hot编码也以相同的比例相乘,从而构造出新的数据集。本质上,mixup在成对样本及其标签的凸组合(convex combinations)上训练神经网络,可以规范神经网络,增强训练样本之间的线性表达。其优点是:
- 改善了网络模型的泛化能力
- 减少对错误标签的记忆
- 增加对抗样本的鲁棒性
- 稳定训练过程
本文提出了针对目标检测的视觉连贯的mixup方法(Visually Coherent Image Mixup for Object Detection),操作流程如下图所示:
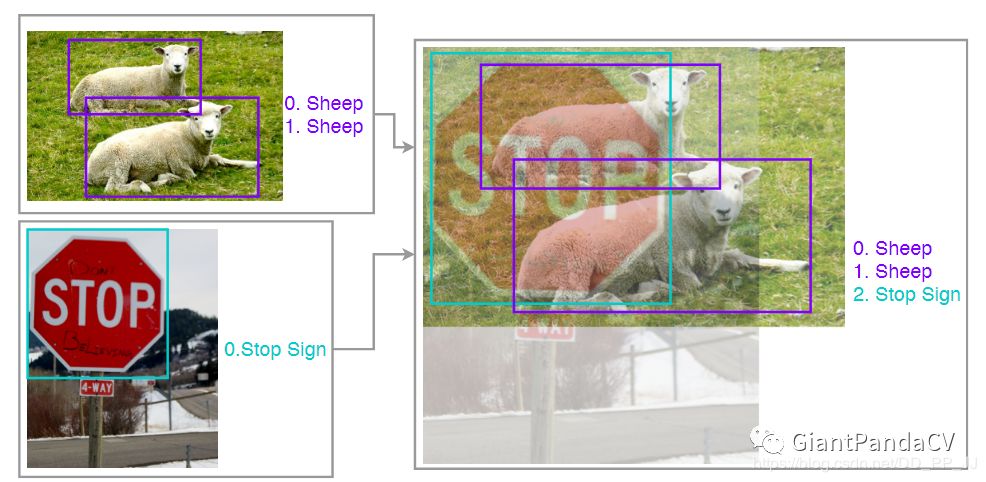
通过上图也很容易理解,但在这里要引入一篇有意思的工作,指出了当时SOTA的目标检测器的缺陷,论文名称为:“Elephant in the room”。注意两张图结合的方式是直接叠加, 取最大的宽高,不进行resize。
大象通常都出现在自然场景下,数据集中是不存在背景是室内的图片的,Elephant in the room就是作者将大象图片抠出,然后直接放在室内场景下,并使用SOTA目标检测器进行检测,如下图所示:

可以看到使用SOTA(faster rcnn nas coco)检测大象的效果并不是很好,而且大象位置不同,也会给其他目标检测的效果带来影响,比如说上图中(d)和(f)图中cup这个对象没有被检测出来。

上图是一个猫在不同的背景下的检测结果,可以看到虽然ROI中内容大体不变,但是结果却有比较大的变化,这叫做特征干扰,同一个目标在不同背景被检测为不同的物体,在ROI之外的特征对最终结果会产生影响,这代表特征干扰对检测过程产生干扰,对检测结果产生不利影响。
针对以上问题,本文提出的是视觉连贯的mixup方法可以比较好的解决,如下图所示:

可以看到,上图中使用了视觉连贯的mixup方法之后,“Elephant in the room”也可以很有效的被检测出来,可以比较好的解决“Elephant in the room”这个问题。
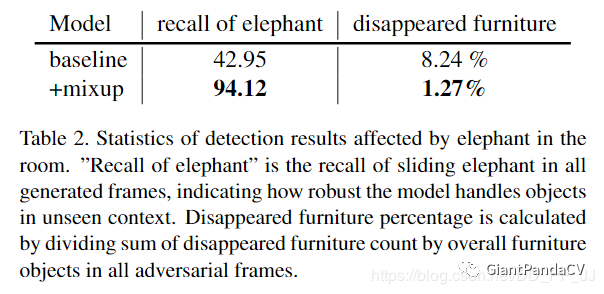
作者也用实验证明了使用这种mixup可以让大象的召回率大幅度提升,并且对其他目标影响降低到了1.27%
Classfication Head Label Smoothing
Label Smoothing也是分类中使用到的trick, 在目标检测问题中也一样适用。Label Smoothing 原理简单来说就是:在分类的时候,比如二分类把原先的标签(0,1) (称为hard target) 转成 soft target,具体方法就是 y‘ = y (1 − α) + α/K 这里α 是个超参数常量,K就是类别的个数 。
数据预处理
在图像分类问题中,一般都会使用随机扰乱图片的空间特征的方法来进行数据增强, 比如随机翻转、旋转、抠图等。这些方法都可以提高模型的准确率、避免过拟合。
这部分主要对以下几种增强方法进行试验:
- 随机几何变换:随机抠图、随机膨胀、随机水平翻转和随机resize。
- 随机颜色抖动:亮度、色调、饱和度、对比度。
其他
训练策略:使用余弦学习率+warmup的方法。

上图是step方法和cosine方法的对比,预先的方法上升更快,不过最终结果比较接近,差的也不是很多。跨卡同步Batch Normalization。
- 多尺度训练,和YOLOv3中的训练方式一样。从{320,352,384,416,448,480,512,544,576,608 }中选择一个尺度进行训练。
实验
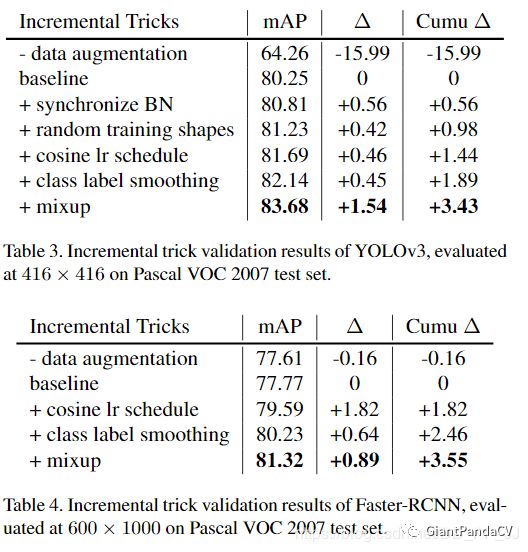
上图分别展示了在YOLOv3和Faster-RCNN上使用以上trick后的效果。其他实验结果就不一一列举了,感兴趣可以仔细读一下paper。
补充
ASFF这篇论文被很多人认为是YOLO中最强的改进版本,不仅仅是他提出的ASFF模块,更因为他有一个非常强的、融合了很多trick的baseline。
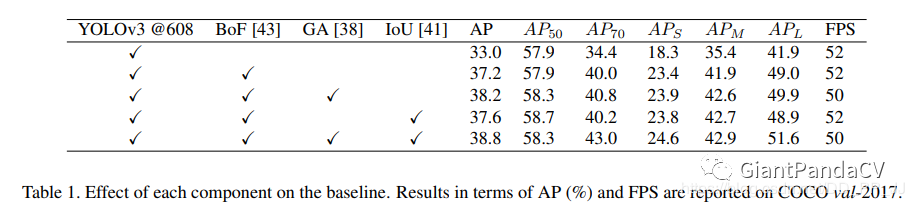
上表中的BoF代表的就是以上解读的这篇:《Bag of Freebies for Training Object Detection Neural Networks》,可以通过对比看到提高了大约4个百分点。IoU代表的是使用了IoU loss,GA代表Guided Anchoring, GA主要是用于解决特征不对齐和anchor设置的问题(这也是一阶段检测方法的弱点),如下图所示,具体讲解可以看:https://zhuanlan.zhihu.com/p/55854246

实际上ASFF模型带来的提升只有1个百分点左右,而以上结合了各种trick的强大的baseline是ASFF出彩的一个强有力的保证。
以上涉及到的trick的具体实现应该可以在ASFF官方实现中找到:https://github.com/ruinmessi/ASFF

