CVPR 2018 Cascade R-CNN
前言
Cascade R-CNN这个算法是CVPR 2018提出的,通过级联多个检测网络达到不断优化预测结果的目的。但是和普通的级联检测器不同,Cascade R-CNN的多个检测网络是基于不同的IOU阈值进而确定不同的正负样本训练出来的,在COCO数据集上Cascade R-CNN取得了非常出色的结果,并且也成为了当前目标检测比赛中的有力Trick。
简单回顾R-CNN结构

首先,以经典的Faster R-CNN为例。整个网络可以分为两个阶段,training阶段和inference阶段,如上图所示。
- training阶段,RPN网络提出了2000左右的proposals,这些proposals被送入到Fast R-CNN结构中,在Fast R-CNN结构中,首先计算每个proposal和gt之间的iou,通过人为的设定一个IoU阈值(通常为0.5),把这些Proposals分为正样本(前景)和负样本(背景),并对这些正负样本采样,使得他们之间的比例尽量满足(1:3,二者总数量通常为128),之后这些proposals(128个)被送入到Roi Pooling,最后进行类别分类和box回归。
- inference阶段,RPN网络提出了300左右的proposals,这些proposals被送入到Fast R-CNN结构中,和training阶段不同的是,inference阶段没有办法对这些proposals采样(inference阶段肯定不知道gt的,也就没法计算iou),所以他们直接进入Roi Pooling,之后进行类别分类和box回归。
在这里插一句,在R-CNN中用到IoU阈值的有两个地方,分别是Training时Positive与Negative判定,和Inference时计算mAP。论文中强调的IoU阈值指的是Training时Positive和Negative判定处。
出发点
下面的Figure1展示了Cascade R-CNN的出发点。
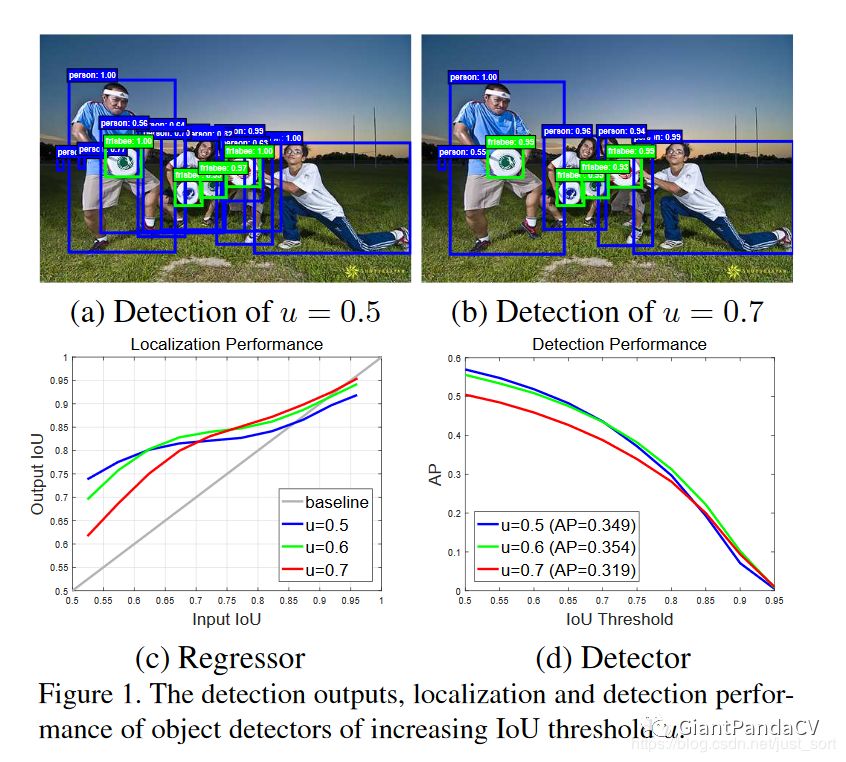
Figure1(a)展示了当IOU阈值等于0.5时的检测结果,可以看到结果图中存在较多误检,因为0.5的阈值会使得正样本中有较多的背景,这是产生误检的主要原因。Figure1(b)展示了当IOU阈值等于0.7时的检测结果,可以看到误检变少了,但是并不一定误检变少了结果就一定更好,因为IOU阈值更大导致正样本越少,那么过拟合的风险就越大。Figure1(c)展示了模型定位表现,其中横坐标表示输入候选框和GT框的IOU值,即proposal的IoU,纵坐标表示输出的候选框和GT框的IOU值, 即经过box reg得到的新的IoU。然后,红,绿,蓝三条曲线分别代表训练检测模型时用的正负样本标签的阈值分别是0.7,0.6,0.5。可以看到当一个检测模型采用某个IOU阈值(假设u=0.6)来判定正负样本时,那么当输入候选框和GT的IOU在这个阈值(u=0.6)附近时,该检测模型比基于其它阈值的检测模型效果更好。Figure1(d)展示了使用不同阈值来训练检测模型的表现,可以看出当IOU阈值等于0.7的时候效果下降比较明显,原因是IOU阈值过高导致正样本数量更少,这样样本会更加不平衡并且容易导致过拟合。
Cascade R-CNN原理
基于上面的出发点,Cascade R-CNN横空出世。简单来说,Cascade R-CNN就是由一系列检测器组成的级联检测模型,并且每个检测器都基于不同IOu阈值的正负样本训练得到,前一个检测器的输出作为后一个检测器的输入,并且越往后走,检测器的阈值是越大的。
为什么Cascade R-CNN要这样来设计呢?这和上面的出发点密切相关,从Figure1(c)中我们看出使用不同的IOU阈值训练得到的检测模型对有不同IOU阈值的输入候选框的结果差别较大,因此我们希望训练每个检测模型用的IOU阈值要尽可能和输入候选框的IOU接近。并且从Figure1(c)中可以看出三条彩色曲线都在灰度曲线上方,这说明对于这几个阈值来说,输出的IOU阈值都大于输入的IOU阈值。根据这一特点,我们就可以拿上一个阶段的输出作为下一个阶段的输入,这样就可以得到越来越高的IOU。
总结一下,我们很难让一个在指定IOU阈值界定的训练集上训练得到的检测模型对IOU跨度较大的输入候选框都达到最佳,因此采取级联的方式能够让每一个阶段的检测器都专注于检测IOU在某一范围内的候选框,因为输出IOU普遍大于输入IOU,因此检测效果会越来越好。
Cascade R-CNN网络结构
下面的Figure3展示了和Cascade R-CNN有关的几种经典检测网络结构的示意图。
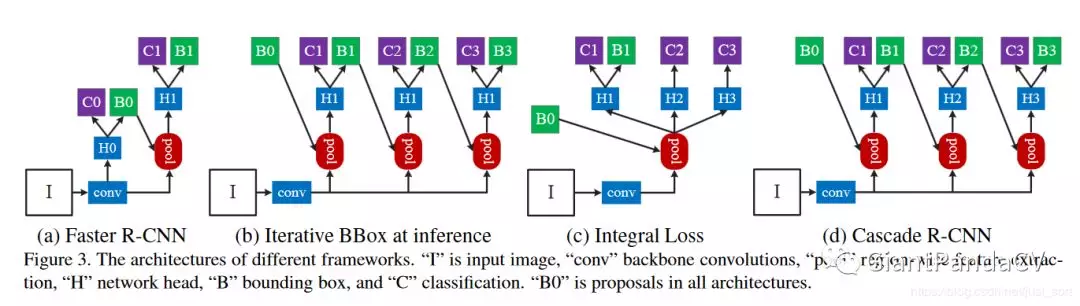
Figure3(a)表示Faster RCNN,因为双阶段类型的目标检测算法基本上都基于Faster RCNN,所以这里也以该算法为BaseLine。其中H0代表的是RPN网络,H1代表的是Faster R-CNN进行检测与分类的head,C1代表最终的分类结果,B1代表最终的bounding box回归结果。Figure3(b)表示迭代式的边界框回归,从图也非常容易看出思想,就是前一个检测模型回归得到的边界框坐标初始化下一个检测模型的边界框,然后继续回归,这样迭代三次后得到结果。Figure3(c)表示Integral Loss,表示对输出边界框的标签界定采用不同的IOU阈值,因为当IOU较高时,虽然预测得到边界框很准确,但是也会丢失一些边界框。(即分类结果基于不同IOU,bbox并没有)关于这个网络的解释看原文更容易理解:
这种Trick在比赛中比较常用,就是说按照数据集的评价指标来自定义Loss(一般是把和指标相关的那一项加在原始的Loss后面)往往可以取得更好的效果。Figure3(d)表示Cascade R-CNN,H1那一部分是一样的,但是Cascade R-CNN得到B1回归后的检测框后,将其输入到H2部分,继续回归,以此类推到H3部分,使得每次对bounding box都提高一定的精度,已达到提高检测框准确度的作用。(注:级联的方式,不再是为了找到hard negatives,而是通过调整bounding boxes,给下一阶段找到一个IoU更高的正样本来训练。),和Figure3(b),Figure3(c)的结构比较像。但和Figure3(b)最主要的区别是Cascade R-CNN中的检测模型是基于前一阶段的输出进行训练,而不是Figure3(b)中3个检测模型都是基于最初始的数据进行训练,(个人理解:head相同,相当于基于最开始训练)而且(b)是在验证阶段采用的方式,而cascade-R-CNN是在训练和验证阶段采用的方式。而和Figure3(c)的区别更加明显,Cascade R-CNN中每个Stage的输入候选框都是前一个阶段的候选框输出,而却没有这种级联的思想,仅仅是模型基于不同的IOU阈值进行训练得到。
Cascade R-CNN的可行性分析
上面的Figure3(b)中的迭代回归有两个致命缺点:
- 从
Figure1(c)的实验知道基于不同IOU阈值训练的检测模型对不同IOU的候选框输入效果差别很大,因此如果每次迭代都基于相同IOU阈值的数据进行训练获得的检测模型,那么当输入候选框的IOU不在训练的检测模型的IOU附近时,效果不会有太大提升。 - 下面的
Figure2为我们展示了Figure3(b)这种候选框回归在不同阶段的4个坐标回归值的分布情况,可以看到在不同的阶段坐标的分布差异是比较大的,对于这种情况,Figure3(b)的迭代回归模型是无能为力的。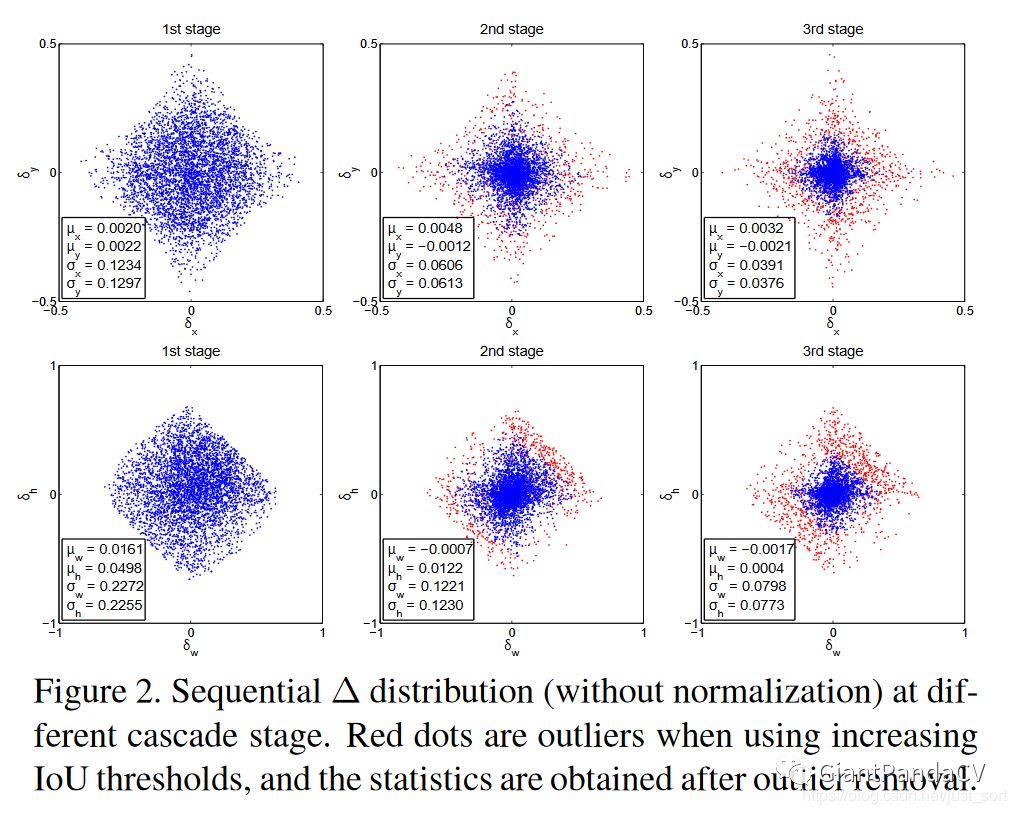
第一行横纵轴分别是回归目标中的box的x方向和y方向偏移量;第二行横纵轴分别是回归目标中的box的宽、高偏差量,$\delta_{x}=\left(g_{x}-b_{x}\right) / b_{w}$, $\delta_{y}=\left(g_{y}-b_{y}\right) / b_{h}$,$\delta_{w}=\log \left(g_{w} / b_{w}\right)$, $\delta_{h}=\log \left(g_{h} / b_{h}\right)$。我们可以看到,从1st stage到2nd stage,proposal的分布其实已经发生很大变化了,因为很多噪声经过box reg实际上也提高了IoU,2nd和3rd中的那些红色点已经属于outliers,如果不提高阈值来去掉它们,就会引入大量噪声干扰,对结果很不利。(head不变,IOU不变还为0.5,去不掉已提高IOU的噪声,也就是红点)从这里也可以看出,阈值的重新选取本质上是一个resample的过程,它保证了样本的质量。
那么Cascade R-CNN是否可以改善上述问题呢?下面的Figure4展示了Cascade R-CNN在不同阶段预测得到的候选框的IOU值分布情况。可以看到,每经过一个检测器进行坐标回归,候选框越准确,也即是说候选框和GT框的IOU更大。从Figure4可以看出,经过检测器之后IOU大的样本增加了,这就说明了Cascade R-CNN是可行的,因为它不会因为后面的检测器提高阈值导致正样本过少而过拟合。
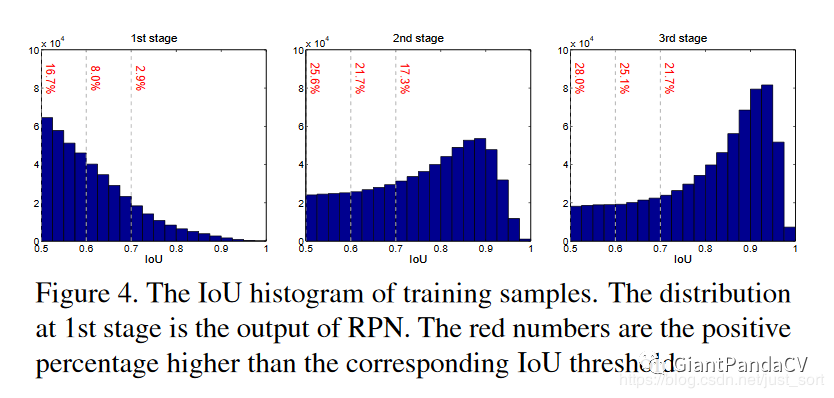
从这张图,我们可以看到,1st stage大于0.5的,到2nd stage大于0.6的,到3rd stage大于0.7的……在这一个过程中proposal的样本数量确实没有特别大的改变,甚至还有稍许提升,和2图结合起来看,应该可以说是非常强有力的证明了。
总结起来,就是:
- cascaded regression不断改变了proposal的分布,并且通过调整阈值的方式重采样(即:$f^{\prime}(x, b)=f_{T} \cdot f_{T-1} \cdot f_{T-2} \cdots f_{1}(x, b)$)
- cascaded在train和inference时都会使用,并没有偏差问题
- cascaded重采样后的每个检测器,都对重采样后的样本是最优的,没有mismatch问题
实验结果
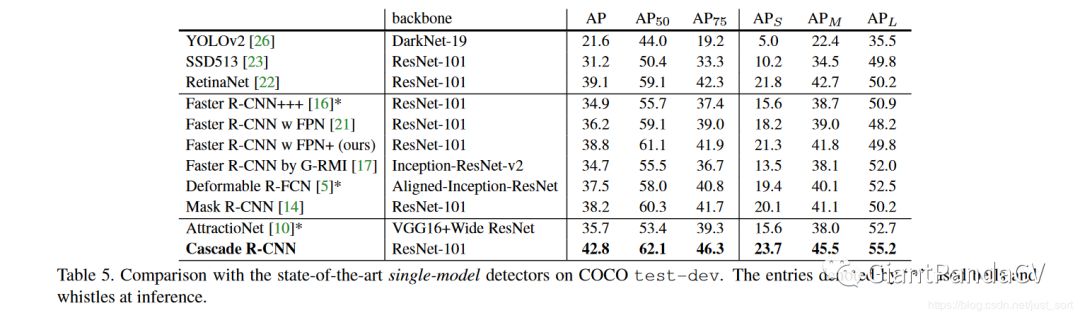
下面的Table1展示了Figure3中几种模型和Cascade R-CNN的结果对比。

然后再来看一下在COCO数据集上的表现,可以看到Cascade R-CNN非常的SOTA了,YOLOV3只有33%的mAP,而Cascade R-CNN则有42.8%的mAP值。