YOLOv2损失函数详解
前言
YOLOv2详细讲解了YOLOv2的算法原理,但官方论文没有像YOLOv1那样提供YOLOv2的损失函数,难怪Ng说YOLO是目标检测中最难懂的算法。今天我们尝试结合DarkNet的源码来分析YOLOv2的损失函数。
关键点回顾
直接位置预测
YOLOv2借鉴RPN网络使用Anchor boxes来预测边界框相对于先验框的offsets。边界框的实际中心位置$(x, y)$需要利用预测的坐标偏移值$\left(t_{x}, t_{y}\right)$,先验框的尺度$\left(w_{a}, h_{a}\right)$以及中心坐标$\left(x_{a}, y_{a}\right)$来计算,这里的${x}_{a}$和${y}_{a}$也即是特征图每个位置的中心点:

上面的公式也是Faster-RCNN中预测边界框的方式。但上面的预测方式是没有约束的,预测的边界框容易向任何方向偏移,例如当$t_{x}=1$时边界框将向右偏移Anchor的一个宽度大小,导致每个位置预测的边界框可以落在图片的任意位置,这就导致模型训练的不稳定性,在训练的时候要花很长时间才可以得到正确的offsets。所以,YOLOv2弃用了这种预测方式,而是沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)。
综上,根据边界框预测的4个偏移值$t_{x}, t_{y}, t_{w}, t_{h}$,可以使用如下公式来计算边界框实际中心位置和长宽,公式在图中:
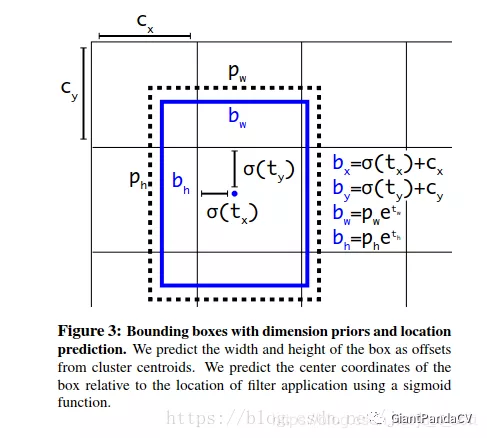
其中,$\left(c_{x}, c_{y}\right)$为cell的左上角坐标。在Fig3中,当前的cell的左上角坐标为$(1,1)$。由于sigmoid函数的处理,边界框的中心位置会被约束在当前cell的内部,防止偏移过多,然后$p_{w}$和$p_{h}$是先验框的宽度与高度,它们的值也是相对于特征图(这里是13 x 13,我们把特征图的长宽记作H,W)大小的,在特征图中的cell长宽均为1。这样我们就可以算出边界框相对于整个特征图的位置和大小了,公式如下:
我们如果将上面边界框的4个值乘以输入图像长宽,就可以得到边界框在原图中的位置和大小了。
细粒度特征
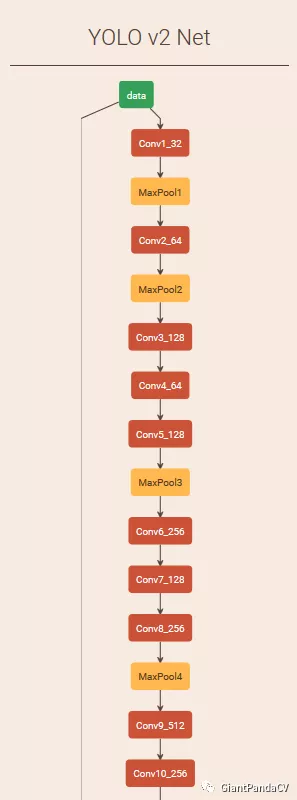
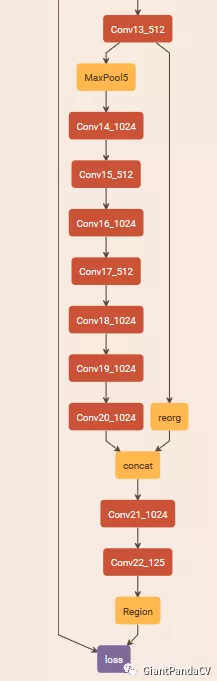
YOLOv2提取Darknet-19最后一个max pool层的输入,得到26x26x512的特征图。经过1x1x64的卷积以降低特征图的维度,得到26x26x64的特征图,然后经过pass through层的处理变成13x13x256的特征图(抽取原特征图每个2x2的局部区域组成新的channel,即原特征图大小降低4倍,channel增加4倍),再与13x13x1024大小的特征图连接,变成13x13x1280的特征图,最后在这些特征图上做预测。使用Fine-Grained Features,YOLOv2的性能提升了1%。这个过程可以在下面的YOLOv2的结构图中看得很清楚:

这个地方今天还要补充一点,那就是passthrough层到底是怎么操作的,在DarkNet中passthough层叫作reorg_layer,可以用下图来表示这个操作:

训练
YOLOv2的训练分为三个阶段,具体就不再赘述了。这里主要重新关注一下训练后的维度变化,我们从上一小节可以看到最后YOLOv2的输出维度是$13 \times 13 \times 125$。这个125使用下面的公式来计算的:
和训练采用的数据集有关系。由于anchors数为5,对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。这里以VOC数据集为例,最终的预测矩阵为$T$,shape为$\left[\text {batch}_{\text {size}}, 13,13,125\right]$,可以将其reshape成[batch_size, $13,13,5,25]$,这样$T[:, :, :, :, 0: 4]$是边界框的位置和大小$\left(t_{x}, t_{y}, t_{w}, t_{h}\right)$,$T[:, :, :, :, 4]$表示边界框的置信度$t_{o}$,$T[:, :, :, :, 5:]$而表示类别预测值。
YOLOv2的模型结构
损失函数
接下来就说一说今天的主题,损失函数。损失函数我看网上的众多讲解,发现有两种解释。
解释1
YOLOv2的损失函数和YOLOv1一样,对于训练集中的ground truth,中心落在哪个cell,那么该cell的5个Anchor box对应的边界框就负责预测它,具体由哪一个预测同样也是根据IOU计算后的阈值来确定的,最后选IOU值最大的那个。这也是建立在每个Cell至多含有一个目标的情下,实际上也基本不会出现多余1个的情况。和ground truth匹配上的先验框负责计算坐标误差,置信度误差以及分类误差,而其它4个边界框只计算置信度误差。这个解释参考的YOLOv2实现是darkflow。源码地址为:https://github.com/thtrieu/darkflow
解释2
在官方提供的Darknet中,YOLOv2的损失函数可以不是和YOLOv1一样的,损失函数可以用下图来进行表示:

可以看到这个损失函数是相当复杂的,损失函数的定义在Darknet/src/region_layer.c中。对于上面这一堆公式,我们先简单看一下,然后我们在源码中去找到对应部分。这里的$W$和$H$代表的是特征图的高宽,都为13,而$A$指的是Anchor个数,YOLOv2中是5,各个$\lambda$值是各个loss部分的权重系数。我们将损失函数分成3大部分来解释:
第一部分:
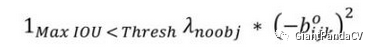
第一项需要好好解释一下,这个loss是计算background的置信度误差,这也是YOLO系列算法的特色,但是用哪些预测框来预测背景呢?这里需要计算各个预测框和所有的ground truth之间的IOU值,并且取最大值记作MaxIOU,如果该值小于一定的阈值,YOLOv2论文取了0.6,那么这个预测框就标记为background,需要计算$\lambda_{n o o b j}$这么多倍的损失函数。为什么这个公式可以这样表达呢?因为我们有物体的话,那么$\lambda_{n o o b j}=0$,如果没有物体$\lambda_{\text {noob} j}=1$,我们把这个值带入到下面的公式就可以推出第一项啦!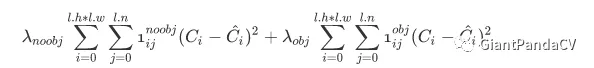
第二部分:
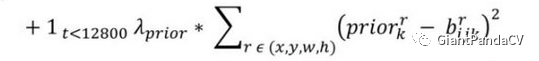
这一部分是计算Anchor boxes和预测框的坐标误差,但是只在前12800个iter计算,这一项应该是促进网络学习到Anchor的形状。第三部分:
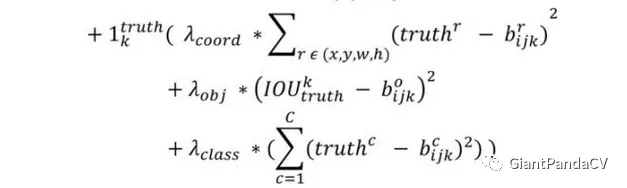
这一部分计算的是和ground truth匹配的预测框各部分的损失总和,包括坐标损失,置信度损失以及分类损失。
3.1 坐标损失 这里的匹配原则是指对于某个特定的ground truth,首先要计算其中心点落在哪个cell上,然后计算这个cell的5个先验框和grond truth的IOU值,计算IOU值的时候不考虑坐标只考虑形状,所以先将Anchor boxes和ground truth的中心都偏移到同一位置,然后计算出对应的IOU值,IOU值最大的先验框和ground truth匹配,对应的预测框用来预测这个ground truth。
3.2 置信度损失 在计算obj置信度时, 增加了一项权重系数,也被称为rescore参数,当其为1时,损失是预测框和ground truth的真实IOU值(darknet中采用了这种实现方式)。而对于没有和ground truth匹配的先验框,除去那些Max_IOU低于阈值的,其它就全部忽略。YOLOv2和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。
3.3 分类损失 这个和YOLOv1一致,没什么好说的了。
我看了一篇讲解YOLOv2损失函数非常好的文章:https://www.cnblogs.com/YiXiaoZhou/p/7429481.html 。里面还有一个关键点:
在计算boxes的$w$和$h$误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale x (2 - truth.w x truth.h)(这里和都归一化到(0,1)),这样对于尺度较小的boxes其权重系数会更大一些,可以放大误差,起到和YOLOv1计算平方根相似的效果。
代码实现
贴一下YOLOv2在Keras上的复现代码,地址为:https://github.com/yhcc/yolo2 。网络结构如下,可以结合上面可视化图来看:
1 | def darknet(images, n_last_channels=425): |
然后,网络经过介绍的损失函数优化训练以后,对网络输出结果进行解码得到最终的检测结果,这部分代码如下:
1 | def decode(detection_feat, feat_sizes=(13, 13), num_classes=80, |
补充
这个损失函数最难的地方应该是YOLOv2利用sigmoid函数计算默认框坐标之后怎么梯度回传,这部分可以看下面的代码(来自Darknet源码):
1 | // box误差函数,计算梯度 |
结合一下前面介绍的公式,这就是一个逆过程。

