AlexeyAB DarkNet BN层代码详解(batchnorm_layer.c)
BatchNorm原理

这是论文中给出的对BatchNorm的算法流程解释,这篇推文的目的主要是推导和从源码角度解读BatchNorm的前向传播和反向传播,就不关注具体的原理了(实际上是因为BN层的原理非常复杂),我们暂时知道BN层是用来调整数据分布,降低过拟合的就够了。
前向传播推导
前向传播实际就是将Algorithm1的4个公式转化为编程语言,这里先贴一段CS231N官方提供的代码:
1 | def batchnorm_forward(x, gamma, beta, bn_param): |
就是一个公式带入的问题,这里倒是没啥好说的,不过了为了和下面反向传播对比理解,这里我们明确每一个张量的维度:
- x shape为(N,D),可以将N看成batch size,D看成特征图展开为1列的元素个数
- gamma shape为(D,)
- beta shape为(D,)
- running_mean shape为(D,)
- running_var shape为(D,)
请特别注意滑动平均(影子变量)这种Trick的引入,目的是为了控制变量更新的速度,防止变量的突然变化对变量的整体影响,这能提高模型的鲁棒性。
反向传播推导
这才是重点,现在做一些约定:
- $\delta$为一个Batch所有样本的方差
- $\mu$为样本均值
- $\hat{x}$为归一化后的样本数据
- $y_{i}$为输入样本$x_{i}$经过尺度变化的输出量
- $\gamma$和$\beta$为尺度变化系数
- $\frac{\partial L}{\partial y}$是上一层的梯度,并假设$x$和$y$都是$(\mathrm{N}, \mathrm{D})$维,即有N个维度为D的样本在BN层的前向传播中$x_{i}$通过$\gamma, \beta, \hat{x}$将$x_{i}$变换为$y_{i}$,那么反向传播则是根据$\frac{\partial L}{\partial y_{i}}$求得$\frac{\partial L}{\partial \gamma}, \frac{\partial L}{\partial \beta}, \frac{\partial L}{\partial x_{i}}$
- 求解$\frac{\partial L}{\partial \gamma}$ $\frac{\partial L}{\partial \gamma}=\sum_{i} \frac{\partial L}{\partial y_{i}} \frac{\partial y_{i}}{\partial \gamma}=\sum_{i} \frac{\partial L}{\partial y_{i}} \hat{x}$
- 求解$\frac{\partial L}{\partial \beta}$ $\frac{\partial L}{\partial \beta}=\sum_{i} \frac{\partial L}{\partial y_{i}} \frac{\partial y_{i}}{\partial \beta}=\sum_{i} \frac{\partial L}{\partial y_{i}}$
- 求解$\frac{\partial L}{\partial x_{i}}$根据论文的公式和链式法则可得下面的等式: $\frac{\partial L}{\partial x_{i}}=\frac{\partial L}{\partial \widehat{x}_{i}} \frac{\partial \widehat{x}_{i}}{\partial x_{i}}+\frac{\partial L}{\partial \sigma} \frac{\partial \sigma}{\partial x_{i}}+\frac{\partial L}{\partial \mu} \frac{\partial \mu}{\partial x_{i}}$我们这里又可以先求$\frac{\partial L}{\partial \hat{x}}$
- $\frac{\partial L}{\partial \hat{x}}=\frac{\partial L}{\partial y} \frac{\partial y}{\partial \hat{x}}=\frac{\partial L}{\partial y} \gamma$ (1)
- $\frac{\partial L}{\partial \sigma}=\sum_{i} \frac{\partial L}{\partial y_{i}} \frac{\partial y_{i}}{\partial \hat{x}_{i}} \frac{\partial \hat{x}_{i}}{\partial \sigma}=-\frac{1}{2} \sum_{i} \frac{\partial L}{\partial \widehat{x}_{i}}\left(x_{i}-\mu\right)(\sigma+\varepsilon)^{-1.5}$ (2)
- $\frac{\partial L}{\partial \mu}=\frac{\partial L}{\partial \hat{x}} \frac{\partial \hat{x}}{\partial \mu}+\frac{\partial L}{\partial \sigma} \frac{\partial \sigma}{\partial \mu}=\sum_{i} \frac{\partial L}{\partial \hat{x}_{i}} \frac{-1}{\sqrt{\sigma+\varepsilon}}+\frac{\partial L}{\partial \sigma} \frac{-2 \Sigma_{i}\left(x_{i}-\mu\right)}{N}$ (3)
- 有了(1) (2) (3)就可以求出$\frac{\partial L}{\partial x_{i}}$
$\frac{\partial L}{\partial x_{i}}=\frac{\partial L}{\partial \widehat{x}_{i}} \frac{\partial \widehat{x}_{i}}{\partial x_{i}}+\frac{\partial L}{\partial \sigma} \frac{\partial \sigma}{\partial x_{i}}+\frac{\partial L}{\partial \mu} \frac{\partial \mu}{\partial x_{i}}=\frac{\partial L}{\partial \hat{x}_{i}} \frac{1}{\sqrt{\sigma+\varepsilon}}+\frac{\partial L}{\partial \sigma} \frac{2\left(x_{i}-\mu\right)}{N}+\frac{\partial L}{\partial \mu} \frac{1}{N}$
到这里就推到出了BN层的反向传播公式了,和论文中一样,截取一下论文中的结果图:
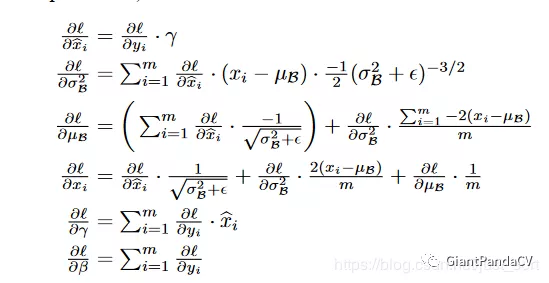
贴一份CS231N反向传播代码:
1 | def batchnorm_backward(dout, cache): |
DarkNet代码详解
1. 构造BN层
构造BN层的代码在src/batchnorm_layer.c中实现,详细代码如下:
1 | layer make_batchnorm_layer(int batch, int w, int h, int c, int train) |
2.前向传播公式实现
DarkNet中在src/blas.h中实现了前向传播的几个公式:
1 | /* |
3. 前向传播和反向传播接口函数
DarkNet在src/batchnorm_layer.c中实现了前向传播和反向传播的接口函数:
1 | // BN层的前向传播函数 |
4.反向传播函数公式实现
其中反向传播的函数如下,就是利用推导出的公式来计算:
1 | // 这里是对论文中最后一个公式的缩放系数求梯度更新值 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yuan!
相关推荐

评论