AlexeyAB DarkNet池化层代码详解(maxpool_layer.c)
|字数总计:3.6k|阅读时长:13分钟|阅读量:
原理
为了图文并茂的解释这个层,我们首先来说一下池化层的原理,池化层分为最大池化以及平均池化。最大池化可以用下图表示:
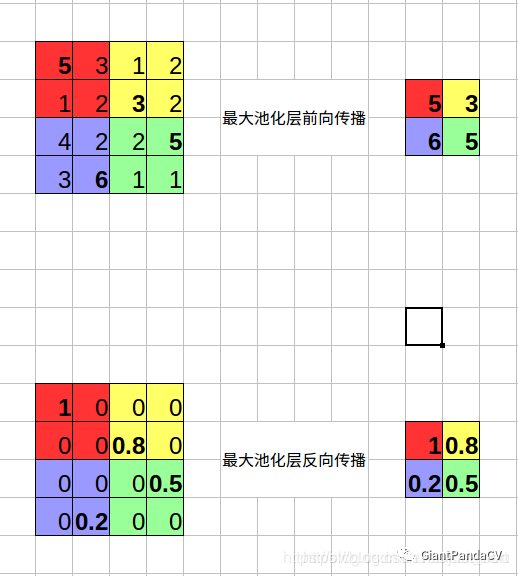
可以看到最大池化层需要记录池化输出特征图的每个值是由原始特征图中哪个值得来的,也就是需要额外记录一个最大值在原图的中的索引。而平均池化只需要将上面的求最大值的操作换成求平均的操作即可,因为是平均操作所以就没必要记录索引了。
池化层的构造
池化层的构造由make_maxpool_layer函数实现,虽然名字是构造maxpool_layer,但其实现也考虑了平均池化,也就是说通过参数设置可以将池化层变成平均池化。这一函数的详细讲解请看如下代码,为了美观,我去掉了一些无关代码,完整代码请到github查看。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
maxpool_layer make_maxpool_layer(int batch, int h, int w, int c, int size, int stride_x, int stride_y, int padding, int maxpool_depth, int out_channels, int antialiasing, int avgpool, int train)
{
maxpool_layer l = { (LAYER_TYPE)0 };
l.avgpool = avgpool;
if (avgpool) l.type = LOCAL_AVGPOOL;
else l.type = MAXPOOL;
l.train = train;
const int blur_stride_x = stride_x;
const int blur_stride_y = stride_y;
l.antialiasing = antialiasing;
if (antialiasing) {
stride_x = stride_y = l.stride = l.stride_x = l.stride_y = 1;
}
l.batch = batch;
l.h = h;
l.w = w;
l.c = c;
l.pad = padding;
l.maxpool_depth = maxpool_depth;
l.out_channels = out_channels;
if (maxpool_depth) {
l.out_c = out_channels;
l.out_w = l.w;
l.out_h = l.h;
}
else {
l.out_w = (w + padding - size) / stride_x + 1;
l.out_h = (h + padding - size) / stride_y + 1;
l.out_c = c;
}
l.outputs = l.out_h * l.out_w * l.out_c;
l.inputs = h*w*c;
l.size = size;
l.stride = stride_x;
l.stride_x = stride_x;
l.stride_y = stride_y;
int output_size = l.out_h * l.out_w * l.out_c * batch;
if (train) {
if (!avgpool) l.indexes = (int*)xcalloc(output_size, sizeof(int));
l.delta = (float*)xcalloc(output_size, sizeof(float));
}
l.output = (float*)xcalloc(output_size, sizeof(float));
if (avgpool) {
l.forward = forward_local_avgpool_layer;
l.backward = backward_local_avgpool_layer;
}
else {
l.forward = forward_maxpool_layer;
l.backward = backward_maxpool_layer;
}
#ifdef GPU
if (avgpool) {
l.forward_gpu = forward_local_avgpool_layer_gpu;
l.backward_gpu = backward_local_avgpool_layer_gpu;
}
else {
l.forward_gpu = forward_maxpool_layer_gpu;
l.backward_gpu = backward_maxpool_layer_gpu;
}
if (train) {
if (!avgpool) l.indexes_gpu = cuda_make_int_array(output_size);
l.delta_gpu = cuda_make_array(l.delta, output_size);
}
l.output_gpu = cuda_make_array(l.output, output_size);
create_maxpool_cudnn_tensors(&l);
if (avgpool) cudnn_local_avgpool_setup(&l);
else cudnn_maxpool_setup(&l);
#endif
l.bflops = (l.size*l.size*l.c * l.out_h*l.out_w) / 1000000000.;
return l;
}
|
最大池化层的前向传播
AlexeyAB DarkNet的池化层和原始的DarkNet的池化层最大的不同在于新增了一个l.maxpool_depth参数,如果这个参数不为0,那么池化层需要每隔l.out_channels个特征图执行最大池化,注意这个参数只对最大池化有效。池化层的前向传播函数为forward_maxpool_layer,详细解释如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
|
void forward_maxpool_layer(const maxpool_layer l, network_state state)
{
if (l.maxpool_depth)
{
int b, i, j, k, g;
for (b = 0; b < l.batch; ++b) {
#pragma omp parallel for
for (i = 0; i < l.h; ++i) {
for (j = 0; j < l.w; ++j) {
for (g = 0; g < l.out_c; ++g)
{
int out_index = j + l.w*(i + l.h*(g + l.out_c*b));
float max = -FLT_MAX;
int max_i = -1;
for (k = g; k < l.c; k += l.out_c)
{
int in_index = j + l.w*(i + l.h*(k + l.c*b));
float val = state.input[in_index];
max_i = (val > max) ? in_index : max_i;
max = (val > max) ? val : max;
}
l.output[out_index] = max;
if (l.indexes) l.indexes[out_index] = max_i;
}
}
}
}
return;
}
if (!state.train && l.stride_x == l.stride_y) {
forward_maxpool_layer_avx(state.input, l.output, l.indexes, l.size, l.w, l.h, l.out_w, l.out_h, l.c, l.pad, l.stride, l.batch);
}
else
{
int b, i, j, k, m, n;
int w_offset = -l.pad / 2;
int h_offset = -l.pad / 2;
int h = l.out_h;
int w = l.out_w;
int c = l.c;
for (b = 0; b < l.batch; ++b) {
for (k = 0; k < c; ++k) {
for (i = 0; i < h; ++i) {
for (j = 0; j < w; ++j) {
int out_index = j + w*(i + h*(k + c*b));
float max = -FLT_MAX;
int max_i = -1;
for (n = 0; n < l.size; ++n) {
for (m = 0; m < l.size; ++m) {
int cur_h = h_offset + i*l.stride_y + n;
int cur_w = w_offset + j*l.stride_x + m;
int index = cur_w + l.w*(cur_h + l.h*(k + b*l.c));
int valid = (cur_h >= 0 && cur_h < l.h &&
cur_w >= 0 && cur_w < l.w);
float val = (valid != 0) ? state.input[index] : -FLT_MAX;
max_i = (val > max) ? index : max_i;
max = (val > max) ? val : max;
}
}
l.output[out_index] = max;
if (l.indexes) l.indexes[out_index] = max_i;
}
}
}
}
}
if (l.antialiasing) {
network_state s = { 0 };
s.train = state.train;
s.workspace = state.workspace;
s.net = state.net;
s.input = l.output;
forward_convolutional_layer(*(l.input_layer), s);
memcpy(l.output, l.input_layer->output, l.input_layer->outputs * l.input_layer->batch * sizeof(float));
}
}
|
最大池化层的反向传播
池化层的反向传播由backward_maxpool_layer实现,反向传播实际上比前向传播更加简单,你可以停下来想想为什么,再看我下面的详细解释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
void backward_maxpool_layer(const maxpool_layer l, network_state state)
{
int i;
int h = l.out_h;
int w = l.out_w;
int c = l.out_c;
#pragma omp parallel for
for(i = 0; i < h*w*c*l.batch; ++i){
int index = l.indexes[i];
state.delta[index] += l.delta[i];
}
}
|
平均池化层的前向传播和反向传播
刚才已经讲到了,最大池化以及平均池化整理是非常类似的,只是把最大的算术操作换成平均,然后平均池化层的反向传播就完成了,具体的代码可以去github项目中查看。
