AlexeyAB DarkNet卷积层的反向传播解析
前言
前面已经详细讲解了卷积层的前向传播过程,大致思路就是使用im2col方法对数据进行重排,然后利用sgemm算法计算出结果,反向传播实际上就是前向传播的逆过程,我们一起来分析一下源码吧。
反向传播解析
- 首先调用
gradient_array()计算当前层l所有输出元素关于加权输入的导数值(也即激活函数关于输入的导数值),并乘上上一次调用backward_convolutional_layer()还没计算完的l.delta,得到当前层最终的敏感度图。这部分的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/*
** 计算激活函数对加权输入的导数,并乘以delta,得到当前层最终的delta(敏感度图)
** 输入:x 当前层的所有输出(维度为l.batch * l.out_c * l.out_w * l.out_h)
** n l.output的维度,即为l.batch * l.out_c * l.out_w * l.out_h(包含整个batch的)
** ACTIVATION 激活函数类型
** delta 当前层敏感度图(与当前成输出x维度一样)
** 说明1:该函数不但计算了激活函数对于加权输入的导数,还将该导数乘以了之前完成大部分计算的敏感度图delta(对应元素相乘),因此调用改函数之后,将得到该层最终的敏感度图
** 说明2:这里直接利用输出值求激活函数关于输入的导数值是因为神经网络中所使用的绝大部分激活函数,其关于输入的导数值都可以描述为输出值的函数表达式,
比如对于Sigmoid激活函数(记作f(x)),其导数值为f(x)'=f(x)*(1-f(x)),因此如果给出y=f(x),那么f(x)'=y*(1-y),只需要输出值y就可以了,不需要输入x的值,
(暂时不确定darknet中有没有使用特殊的激活函数,以致于必须要输入值才能够求出导数值,在activiation.c文件中,有几个激活函数暂时没看懂,也没在网上查到)。
** 说明3:关于l.delta的初值,可能你有注意到在看某一类型网络层的时候,比如卷积层中的backward_convolutional_layer()函数,没有发现在此之前对l.delta赋初值的语句,
** 只是用calloc为其动态分配了内存,这样的l.delta其所有元素的值都为0,那么这里使用*=运算符得到的值将恒为0。是的,如果只看某一层,或者说某一类型的层,的确有这个疑惑,
** 但是整个网络是有很多层的,且有多种类型,一般来说,不会以卷积层为最后一层,而回以COST或者REGION为最后一层,这些层中,会对l.delta赋初值,又由于l.delta是由后
** 网前逐层传播的,因此,当反向运行到某一层时,l.delta的值将都不会为0.
*/
void gradient_array(const float *x, const int n, const ACTIVATION a, float *delta)
{
int i;
for(i = 0; i < n; ++i){
delta[i] *= gradient(x[i], a);
}
}
gradient函数的代码如下:
1 | /* |
- 然后,如果网络进行了BN,则调用backward_batchnorm_layer,否则直接调用 backward_bias()计算当前层所有卷积核的偏置更新值。backward_batchnorm_layer之后会单独讲,这里来看看backward_bias()的实现。
1 | /* |
- 接下来依次调用im2col_cpu(),gemm_nt()函数计算当前层权重系数更新值;如果上一层的delta已经动态分配了内存,则依次调用gemm_tn(), col2im_cpu()计算上一层的敏感度图(并未完成所有计算,还差一个步骤)。整个反向传播的核心函数解释如下:
1 | /* |
col2im函数解析
col2im函数是im2col的逆过程,代码在src/col2im.c中实现,具体如下:
1 | // 注释来自https://github.com/hgpvision/darknet/blob/master/src/col2im.c |
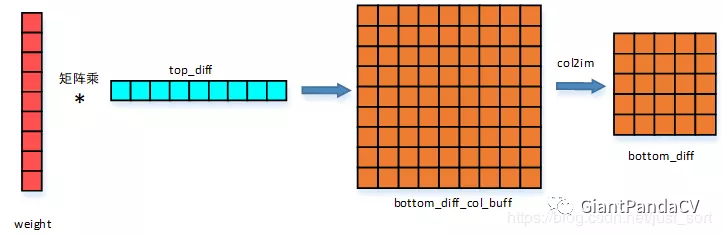
图示
上面介绍的反向传播可以用下图来表示,更容易理解。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yuan!
相关推荐

评论