# Darknet Header self.version = np.array([0, 2, 5], dtype=np.int32) # (int32) version info: major, minor, revision self.seen = np.array([0], dtype=np.int64) # (int64) number of images seen during training
withopen(path, 'r') as f: lines = f.read().split('\n')
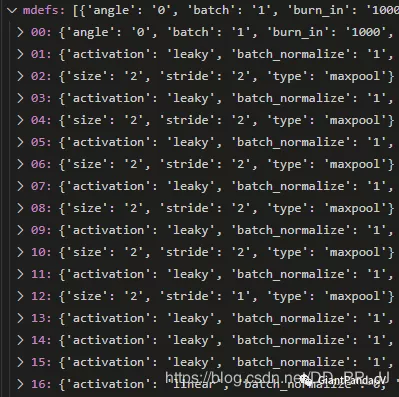
# 去除以#开头的,属于注释部分的内容 lines = [x for x in lines if x andnot x.startswith('#')] lines = [x.rstrip().lstrip() for x in lines] mdefs = [] # 模块的定义 for line in lines: if line.startswith('['): # 标志着一个模块的开始 ''' 比如: [shortcut] from=-3 activation=linear ''' mdefs.append({}) mdefs[-1]['type'] = line[1:-1].rstrip() if mdefs[-1]['type'] == 'convolutional': mdefs[-1]['batch_normalize'] = 0 # pre-populate with zeros (may be overwritten later) else: # 将键和键值放入字典 key, val = line.split("=") key = key.rstrip()
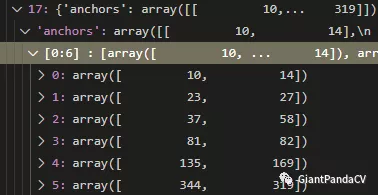
if'anchors'in key: mdefs[-1][key] = np.array([float(x) for x in val.split(',')]).reshape((-1, 2)) # np anchors else: mdefs[-1][key] = val.strip()
# 判断所有参数中是否有不符合要求的key f = [] for x in mdefs[1:]: [f.append(k) for k in x if k notin f] u = [x for x in f if x notin supported] # unsupported fields assertnotany(u), "Unsupported fields %s in %s. See https://github.com/ultralytics/yolov3/issues/631" % (u, path)
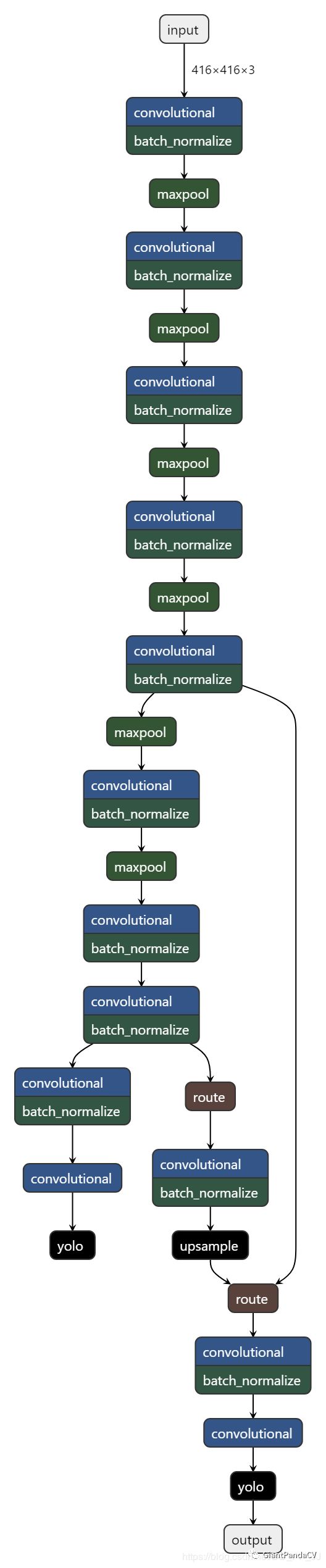
elif mdef['type'] == 'route': # nn.Sequential() placeholder for 'route' layer layers = [int(x) for x in mdef['layers'].split(',')] filters = sum( [output_filters[i + 1if i > 0else i] for i in layers]) # extend表示添加一系列对象 routs.extend([l if l > 0else l + i for l in layers])
for i, (mdef, module) inenumerate(zip(self.module_defs, self.module_list)): mtype = mdef['type'] if mtype in ['convolutional', 'upsample', 'maxpool']: # 卷积层,上采样,池化层只需要经过即可 x = module(x) elif mtype == 'route': # route操作就是将几个层的内容拼接起来,具体可以看cfg文件解析 layers = [int(x) for x in mdef['layers'].split(',')] iflen(layers) == 1: x = layer_outputs[layers[0]] else: try: x = torch.cat([layer_outputs[i] for i in layers], 1) except: # apply stride 2 for darknet reorg layer layer_outputs[layers[1]] = F.interpolate( layer_outputs[layers[1]], scale_factor=[0.5, 0.5]) x = torch.cat([layer_outputs[i] for i in layers], 1)
elif mtype == 'shortcut': x = x + layer_outputs[int(mdef['from'])] elif mtype == 'yolo': output.append(module(x, img_size)) #记录route对应的层 layer_outputs.append(x if i in self.routs else [])
if self.training: # 如果训练,直接输出YOLO要求的Tensor # 3*(class+5) return output elif ONNX_EXPORT:# 这个是对应的onnx导出的内容 x = [torch.cat(x, 0) for x inzip(*output)] return x[0], torch.cat(x[1:3], 1) # scores, boxes: 3780x80, 3780x4 else: # 对应测试阶段 io, p = list(zip(*output)) # inference output, training output return torch.cat(io, 1), p