
BitComet配置
本文记录对BitComet的一些配置修改,用于备份。 BitCometBitComet(比特彗星)是一款完全免费的BT下载软件,支持断点续传和边下载边播放下载管理软件,也称BT下载客户端,同时也是一个集BT/HTTP/FTP于一体的下载管理器。官网下载地址:BitComet - Downloading 不过还是建议去找第三方修改版能开启种子市场的,有意想不到的福利哦😋 注意事项确保你的网络为公网,路由器也需打开端口映射,没公网的可打电话申请或使用穿透工具等,这里就不介绍了,确保打开软件,右下角两绿灯亮起: 配置网络连接我这里设置下载不限速,也可以根据自己的带宽设置。上传建议比自己最大上传带宽小,不要设置太大,但也不能设置太低(有上传才有下载,人人为我,我为人人!),我这里设置780KB/s。 监听端口建议自己指定一个,不推荐6881-6885 ,16881-16885范围内和一些特殊的端口。 下载目录自己设置合适的下载目录。 任务队列推荐做种任务数拉满,下载任务数不要太大。 BT下载勾选加入DHT,自动反吸血,协议优先,种子存档、种子市场打开,上传无限制或根据自己上传带宽设置 ...
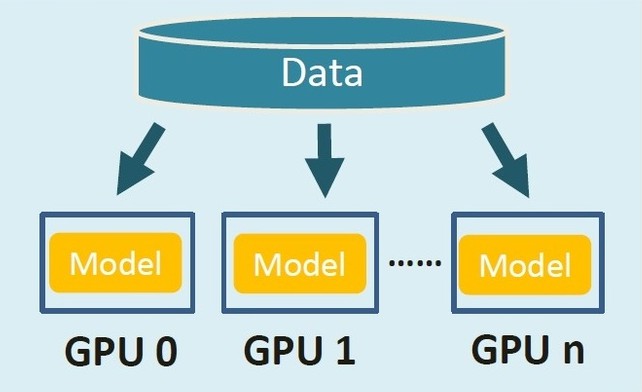
如何使用PyTorch分布式训练
DDPDDP是PyTorch中的一个库,它支持跨多个设备的梯度同步。这意味着您可以通过跨多个GPU并行处理,线性地加快模型训练。DDP的工作原理是为每个GPU创建一个单独的Python进程,每个进程都使用一个不重叠的数据子集。 比起DP来,DDP训练速度更快,显卡负载也更为均衡。目前官方开发者推荐使用DDP代替DP,DP很少维护了,导致有许多bug。比如:nn.ParameterList和nn.ParameterDict在DP中会存在其他卡无法复制,变成空值的Bug,而这在DDP中就正常。 使用① 添加超参数: 1234567def parse(): parser = argparse.ArgumentParser() parser.add_argument('--local_rank', type=int, default=0) ... ... args = parser.parse_args() return args local_rank:进程内GPU编号,非显式参数,由 torch.distributed.launch ...

Grad-CAM原理和实现
本文转载于⚡哥的知乎专栏,大佬写的真是清晰易懂,菜鸡的我默默留存,好好学习!🙇♂️ 觉得不错的,大家记得帮电哥点赞👍+收藏⭐呀! 原理① 要做猫狗的二分类任务,网络的分类器是输出为两个神经元的全连接层,两个神经元的输出分别为$z=\left[z_{c}, z_{d}\right]$,其中猫的概率为$p_c$,狗的概率为$p_d$,且$\left[p_{c}, p_{d}\right]=\operatorname{softmax}(z)$。② 要可视化猫这个类别的GradCAM,通过$z_c$对CNN最后一层的所有特征图$A_{i, j}^{k}$求偏导$G_{i, j}^{k}=\frac{\partial z_{c}}{\partial A_{i, j}^{k}}$,其中$A_{i, j}^{k}$表示特征图$A$ shape=(1, C, H, W)的第k通道的(i, j)坐标点,最终的偏导特征图$G$ shape=(1, C, H, W)。 取最后一层的原因: GradCAM可以用来可视化任何的激活特征图,但论文的主要目的是要解释神经网络得到决策的可能原因。 最后一层特 ...

TensorRT安装
安装PyCuda如果通过Python使用TensorRT的话,需要安装PyCuda,只需要执行: 1pip install pycuda (注:本人测试环境为Ubuntu16.04,在安装过程中发现PyCuda新版本会编译失败,而pycuda<=2019.1则正常。) 若安装出现问题,需手动编译,可参照官网教程: 12345678910git clone https://github.com/inducer/pycuda.git # 测试时新版本为2020.1tar xfz pycuda-VERSION.tar.gzcd pycuda-VERSIONpip3 install numpy==1.20rc # 此处一定要注意版本,本人刚开始安装了1.19,一直不成功python configure.py --cuda-root=/where/ever/you/installed/cuda # 修改为自己cuda的路径su -c "make install"# 测试cd pycuda-VERSION/testpython test_driver.py # ...
解决nvidia-smi和nvcc显示信息与所安装CUDA版本不一致问题
nvidia-smi & nvcc -V首先需明白CUDA有runtime api和driver api,两者都有对应的CUDA版本,nvcc -V显示前者对应的CUDA版本,而nvidia-smi显示后者对应的CUDA版本。 通常,driver api版本能向下兼容runtime api的版本,即nvidia-smi显示的版本大于nvcc -V的版本通常不会出现大问题。因此nvidia-smi显示的版本与所安装CUDA版本不一致是正常的。 而平常我们做深度学习所用的是CUDA的runtime api版本,因此以nvcc -V为准,这里版本如果不一致就容易发生问题。其原因主要是本机存在多个CUDA,没有正确映射造成。 问题解决查询现在的映射关系,可通过如下命令: 1stat /usr/bin/nvcc 要是映射错误,需重新建立映射: ① 删除原来映射 1sudo rm -rf /usr/bin/nvcc ② 建立新的软链接指向安装的CUDA版本 1sudo ln -s /usr/local/cuda/bin/nvcc /usr/bin/nvcc

快速入门Docker
Docker是什么?Docker是一个虚拟环境容器,可以将你的开发环境、代码、配置文件等一并打包到这个容器中,并发布和应用到任意平台中。 Docker的三个概念① 镜像(Image):是一个包含有文件系统的面向Docker引擎的只读模板。任何应用程序运行都需要环境,而镜像就是用来提供这种运行环境的。例如一个Ubuntu镜像就是一个包含Ubuntu操作系统环境的模板。 ② 容器(Container):类似于一个轻量级的沙盒,可以将其看作一个极简的Linux系统环境(包括root权限、进程空间、用户空间和网络空间等),以及运行在其中的应用程序。Docker引擎利用容器来运行、隔离各个应用。容器是镜像创建的应用实例,可以创建、启动、停止、删除容器,各个容器之间是是相互隔离的,互不影响。注意:镜像本身是只读的,容器从镜像启动时,Docker在镜像的上层创建一个可写层,镜像本身不变。 ③ 仓库(Repository):Docker用来集中存放镜像文件的地方。注意与注册服务器(Registry)的区别:注册服务器是存放仓库的地方,一般会有多个仓库;而仓库是存放镜像的地方,一般每个仓库存放一类镜像, ...

Ubuntu多版本CUDA安装与切换
本文主要介绍CUDA多版本如何共存与切换,这里以cuda10.1为例。 安装新版本cuda去官网选择对应安装包,这里选择runfile类型的安装文件cuda_10.1.243_418.87.00_linux.run。 执行以下命令,开始安装:1sudo sh cuda_10.1.243_418.87.00_linux.run 依次出现如下界面: 选择continue,继续。 输入accept,回车接受。 是否安装显卡驱动,本机已有,这里一般取消勾选 是否安装工具包,默认勾选 是否安装样例, 默认勾选 是否安装演示套件,默认勾选 是否安装文档,默认勾选 勾选完毕,点击install开始安装。 过程中会叫你选择是否创建指向cuda的链接: 12Do you want to install a symbolic link at /usr/local/cuda?(y)es/(n)o/(q)uit: 如果马上想要使用当前版本,这里就选yes,否则就选no,等有需要时再设置。 安装cuDNN同样去官网下载好与CUDA版本对应的安装包,文件格式为tar压缩文件cudnn-10.1-linu ...

江南大学学位论文LaTeX模板
本文由🐧从zhuangbo转载 使用教程江南大学博士、硕士学位(毕业)论文 LaTeX 模板。点此下载(提取码: 8ub7) 文档类 jnthesis.cls 基于 ctex 宏包定义了论文格式,包括字体,字号,行距,标题,页眉,页脚,目录,摘要,正文等各种格式。 文件 jn.bst 定义了参考文献格式。 推荐使用 TeXlive 发行版,不推荐使用 CTEX 发行版。 为便于编辑,通常将长文档分成若干文件。本论文模板还提供了以下文件: 文件 说明 root.tex 主文档,整个文档结构,用 XeLaTeX 编译此文档 main.tex 主要内容,包含主要章节内容 cover.doc 封面,DOC 文件,修改编辑后另存为 PDF cover.pdf 封面,PDF 文件,插入文档 statement.doc 声明和授权,DOC 文件,修改编辑后另存为 PDF statement.pdf 声明和授权,PDF 文件,插入文档 setup/settings.tex 用户设置,如:标题,作者,其他宏包和样式等 setup/userdefs.tex ...

keras/tensorflow转onnx
项目中遇到需要将训练好的keras模型转换成onnx以便部署到嵌入式设备进行RT加速,最开始使用的keras2onnx工具,然而此工具支持性并不好,在转化过程中遇到许多问题。因此决定将keras转成tensorflow格式,再使用支持性较好的tf2onnx工具进行转化。 新版本目前keras2onnx停止更新,功能已整合进tf2onnx中,keras模型可直接使用 api tf2onnx.convert.from_keras()完成转换操作 转换步骤:1234567891011import tf2onnximport onnxruntime as rt# 加载模型model = ResNet50(weights='imagenet')# 设置输入大小spec = (tf.TensorSpec((None, 224, 224, 3), tf.float32, name="input"),)# 保存onnx路径output_path = model.name + ".onnx"# 转换tf2onnx.convert.from_ke ...

Leetcode刷题(Python3及Java实现)
本系列是本人在刷题过程中,参考《小浩算法》的题型分类所做。由于小浩在大多数题目并未使用统一的语言实现,这里本人给出了Python和Java的实现。目前Python实现已完成,Java实现仍在更新中。若有错误或者更好的解决方法,欢迎提出。 数组系列1.交集 此题可以看成是一道传统的映射题(map映射),为什么可以这样看呢,因为我们需找出两个数组的交集元素,同时应与两个数组中出现的次数一致。这样就导致了我们需要知道每个值出现的次数,所以映射关系就成了<元素,出现次数> [第349题] 给定两个数组,编写一个函数来计算它们的交集。 示例 1:输入:nums1 = [1,2,2,1], nums2 = [2,2]输出:[2] 示例 2:输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]输出:[9,4] 说明: 输出结果中的每个元素一定是唯一的。 我们可以不考虑输出结果的顺序。 方法一:映射字典 12345678910111213141516171819#Pythonclass Solution: def intersect ...