# 先放置白皇后, cur代表当前行,从0开始一行行遍历 defw_queen(cur=0): # 判断上行放置的棋子是否有问题,如果有则回退 for row inrange(cur-1): # 由于是一行行遍历肯定不存在同行,只需检测是否同列和同对角线 # 若在该列或对角线上存在其他皇后 if w_pos[row] - w_pos[cur-1] == 0orabs(w_pos[row] - w_pos[cur-1]) == cur - 1 - row: # 该位置不能放 return # 当前颜色皇后都正确放置完毕 if cur == n: # 放置另一种颜色的皇后 b_queen(0) return # 遍历每列 for col inrange(n): # 如果该位置为1,则可以放置其子 if chessboard[cur][col] == 1: # 记录该棋子存放位置 w_pos[cur] = col # 继续放下一个皇后 w_queen(cur+1)
# 再放置黑皇后,与白皇后同理 defb_queen(cur=0): global count for row inrange(cur-1): if b_pos[row] - b_pos[cur-1] == 0orabs(b_pos[row] - b_pos[cur-1]) == cur - 1 - row: return if cur == n: # 两种颜色皇后放置完毕,记录次数 count += 1 return for col inrange(n): # 如果该位置为1且没有放白皇后,则可以放置其子 if chessboard[cur][col] == 1and w_pos[cur] != col: b_pos[cur] = col b_queen(cur+1)
# 输入 n = int(input()) # 初始化棋盘 chessboard = [[] for _ inrange(n)] for i inrange(n): arr = input().split() for j inrange(n): chessboard[i].append(int(arr[j])) # 用于记录白皇后位置 w_pos = [0for _ inrange(n)] # 用于记录黑皇后位置 b_pos = [0for _ inrange(n)] # 初始化多少种放法 count = 0 # 开始放置皇后 w_queen(0) # 输出多少种放法 print(count)
defA(k, n): if k == n: return print('sin(%d' % (k + 1), end='') # 若后边还有式子,判断是输出+号还是-号 if k + 1 != n: if k % 2 == 1: print('+', end='') else: print('-', end='') # 若到底了,则输出n个')'结束 else: print(')'*n, end='') k += 1 A(k, n) # 递归调用自身
n = int(input()) for i inrange(n): # 第一项n-1个括号开始 if i == 0: print('('*(n-1), end='') # 后续An+n-i) A(0, i+1) print('+%d' % (n-i), end='') # 最后一项加完整数之和不必再输出右括号 if i != n - 1: print(')', end='')
str1 = '0100110001010001' var = [] for i inrange(1, len(str1)+1): for j inrange(len(str1) - i + 1): if str1[j:j+i] notin var: var.append(str1[j:j+i]) print(len(var))
withopen('num.txt') as file: lines = file.readlines() file.close res = 0 for line in lines: for num in line.split(): if res == 0: res = int(num) else: res *= int(num) count = 0 for i instr(res)[::-1]: if i != '0': break count += 1 print(count)
n, string = input().split() ifint(n) > 1: l = 0 r = int(n) - 1 string = list(string) while l <= r: string[l], string[r] = string[r], string[l] l += 1 r -= 1 print(''.join(string)) else: print(string)
递增三元组
题目描述
在数列 a[1], a[2], …, a[n] 中,如果对于下标 i, j, k 满足 0<i<j<k<n+1 且 a[i]<a[j]<a[k],则称 a[i], a[j], a[k] 为一组递增三元组,a[j]为递增三元组的中心。 给定一个数列,请问数列中有多少个元素可能是递增三元组的中心。
输入描述
输入的第一行包含一个整数 n。 第二行包含 n 个整数 a[1], a[2], …, a[n],相邻的整数间用空格分隔,表示给定的数列。
输出描述
输出一行包含一个整数,表示答案。
输入样例
5 1 2 5 3 5
输出样例
2
样例说明
a[2]和a[4]可能是三元组的中心。
1 2 3 4 5 6 7 8 9 10 11 12 13
n = int(input()) arr = list(map(int, input().split())) count = 0 # 记录该中心是否用过 data = [] for i inrange(n): for j inrange(i + 1, n): for k inrange(j + 1, n): if arr[i] < arr[j] < arr[k]: if arr[j] notin data: data.append(arr[j]) count += 1 print(count)
MAX = 59084709587505 # MAX = 49 a = [3, 5, 7] s = set() tou = 1 whileTrue: for i in a: t = tou * i if t <= MAX: s.add(t) lst = sorted(s) for i in lst: if i > tou: tou = i break if tou >= MAX: break print(len(s)) # 1905
调手表
题目描述
小明买了块高端大气上档次的电子手表,他正准备调时间呢。在 M78 星云,时间的计量单位和地球上不同,M78 星云的一个小时有 n 分钟。大家都知道,手表只有一个按钮可以把当前的数加一。在调分钟的时候,如果当前显示的数是 0 ,那么按一下按钮就会变成 1,再按一次变成 2 。如果当前的数是 n - 1,按一次后会变成 0 。作为强迫症患者,小明一定要把手表的时间调对。如果手表上的时间比当前时间多1,则要按 n - 1 次加一按钮才能调回正确时间。
小明想,如果手表可以再添加一个按钮,表示把当前的数加 k 该多好啊…… 他想知道,如果有了这个 +k 按钮,按照最优策略按键,从任意一个分钟数调到另外任意一个分钟数最多要按多少次。
# 最大公约数 defgcd(a, b): while b != 0: c = a % b a = b b = c return a # 分子 molecule = 0 # 因为1/1 + 1/2 + ... + 1/2^19通分后 # = 2^19/2^19 + 2^18/2^19 + ... + 1/2^19 # 则分子和为2^19 + 2^18 + ... + 1 for i inrange(20): molecule += 2 ** i # 分母为2^19 gc = gcd(molecule, 2 ** 19) # 输出约分后的结果 print(molecule // gc , '/', 2 ** 19 // gc, sep='')
复数求和
题目描述
从键盘读入n个复数(实部和虚部都为整数)用链表存储,遍历链表求出n个复数的和并输出。
输入样例
3 3 4 5 2 1 3
输出样例
9+9i
输入样例
7 1 2 3 4 2 5 1 8 6 4 7 9 3 7
输出样例
23+39i
1 2 3 4 5 6 7 8
n = int(input()) arr = [list(map(int, input().split())) for _ inrange(n)] real = 0 imaginary = 0 for i inrange(n): real += arr[i][0] imaginary += arr[i][1] print(real,'+',imaginary,'i', sep='')
file = open('item.txt', 'r') ans = 0 for line in file.readlines(): price, rate = map(float, line.split()) ans += price * rate / 100 file.close() print(ans)
''' 并查集算法 ''' # 用于找到x的父节点 defrootFind(x): p = x #如果x的父节点不是他本身,就一直循坏到找到父节点为之 while x != pre[x]: x = pre[x] # 压缩路径,这个是优化的,所以可加可不加 while p != x: # 若当前节点不是父节点,找到父节点后,把沿途每个节点的根节点都设成父节点,使树变得扁平,以减小深度 p, pre[p] = pre[p], x return x m, n = map(int, input().split()) cnt = m * n # pre列表中存储的是每个节点的父节点 pre = [i for i inrange(cnt+1)] k = int(input()) for i inrange(k): a,b = map(int, input().split()) roota = rootFind(a) rootb = rootFind(b) if roota != rootb: # 如果父节点不一样就合并, 选任意一方为父 pre[roota] = pre[rootb] #同时合并的话,集合就会少一个 cnt -= 1 print(cnt)
# 总共200元 total = 200 # 由于2元是1元的10倍,即扣掉5元钞票的钱数,应为21的倍数 # 要使换的钱数最少,则5元的钞票要多 for i inrange(1, 200 // 21): total -= 21 if total % 5 == 0: # 共换了多少张钞票 count = 10 * i + i + total // 5 print(count) break
m, n = map(int, input().split()) matrix = [[] for _ inrange(m)] for i inrange(m): arr = input().split() for j inrange(n): matrix[i].append(int(arr[j])) # 初始位置 x, y = 0, 0 # 外框到里框的个数 for i inrange(min(m, n)//2+1): # 向下取数 while x < m and matrix[x][y] != -1: print(matrix[x][y], end=' ') matrix[x][y] = -1# 将去过的位置置为-1 x += 1 # 上个循环结束后x多加一次要减回来 x -= 1 # 列值加1,因为第零列在上个循环已经输出,往右推一行 y += 1 # 向右取数 while y < n and matrix[x][y] != -1: print(matrix[x][y], end=' ') matrix[x][y] = -1# 将去过的位置置为-1 y += 1 # 上个循环多加一次减回来 y -= 1 # 往上推一行 x -= 1 # 向上取数 while x >= 0and matrix[x][y] != -1: print(matrix[x][y], end=' ') matrix[x][y] = -1# 将去过的位置置为-1 x -= 1 # 上个循环使多减一次加回来 x += 1 # 往左推一行 y -= 1 # 向左取数 while y >= 0and matrix[x][y] != -1: print(matrix[x][y], end=' ') matrix[x][y] = -1# 将去过的位置置为-1 y -= 1 # 上个循环多加一次减回来 y += 1 # 向下推一行 x += 1
# 矩阵乘法 defmul_matrix(matrix1, matrix2, n): # 存放乘法后的矩阵 res = [[] for _ inrange(n)] # 遍历每个元素 for i inrange(n): for j inrange(n): pos = 0 # 乘法后所得结果该位置的值等于两个数组该行和该列的加权 for c inrange(n): pos += matrix1[i][c] * matrix2[c][j] res[i].append(pos) return res
# 输入 n, m = map(int, input().split()) matrix = [[] for _ inrange(n)] for i inrange(n): arr = input().split() for j inrange(n): matrix[i].append(int(arr[j]))
# 初始化单位矩阵 res = [[1if i == j else0for j inrange(n)] for i inrange(n)] # m次幂 for i inrange(1, m+1): res = mul_matrix(res, matrix, n)
# 输出结果 for i inrange(n): for j inrange(n): print(res[i][j], end=' ') print()
''' 方法一:暴力求解会超时 # 求最大公约数 def gcd(i, j): while j !=0: k = i % j i, j = j, k return i n = int(input()) sum_arr = 0 mod = 10 ** 9 + 7 for i in range(1, n+1): for j in range(1, n+1): t = gcd(i, j) ** 2 sum_arr += t % mod print(sum_arr) '''
'''方法二:欧拉函数(线性筛法)推荐''' MOD = 10 ** 9 + 7 # 欧拉函数 phi = [] # 存放[1, n/d]中,所有互质对的个数 sum_ = [] # 结果 ans = 0 defeuler_table(n): # 初始化 for _ inrange(n + 1): phi.append(0) sum_.append(0) # n=1时的欧拉函数为1 phi[1] = 1 # 求到n为止的欧拉函数(线性筛法) for i inrange(2, n + 1): # ph[i]为0时代表没遍历过,则此时i为素数 if phi[i] == 0: j = i while j <= n: # 先令phi[j] = j,则ph[j] / i = j / i = i^(k-1) if phi[j] == 0: phi[j] = j # 当i是素数时 phi(i) = i-1 # phi(i^k) = i^(k-1) * (i-1) # 这里j = i^k phi[j] = phi[j] // i * (i - 1) # 进行递推,求得相应的phi[j],使phi[j]上的值不再为0,那么下次遍历i时,若为0,则代表i为素数 j += i sum_[1] = 1 # 递推,求互质对的个数 for i inrange(2, n + 1): sum_[i] = sum_[i - 1] + phi[i] * 2
n = int(input()) euler_table(n) for i inrange(1, n + 1): # 将问题转化成了count(d)*d*d ans = (ans + sum_[n // i] * i % MOD * i) % MOD print(ans)
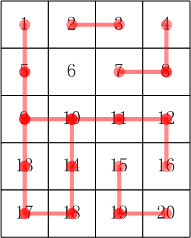
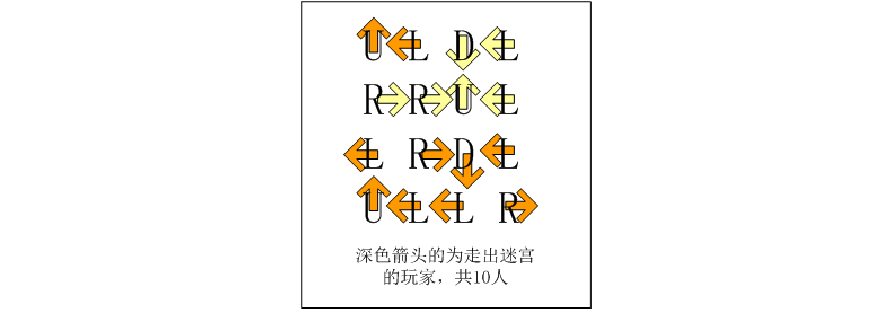
defdfs(x, y): global count global rows global cols # 走出迷宫,计数+1 if x < 0or x > rows-1or y < 0or y > cols-1: count += 1 return # 若当前位置未走过,则标记为走过 if paths[x][y] == 0: paths[x][y] = 1 # 若已走过,则代表回到原路,走不出迷宫,退出 else: return # 获取方向 direction = dataMap[x][y] # 上 if direction == 'U': dfs(x-1, y) # 下 if direction == 'D': dfs(x+1, y) # 左 if direction == 'L': dfs(x, y-1) # 右 if direction == 'R': dfs(x, y+1) # 存储地图 dataMap = [] withopen('迷宫2.txt', mode='r', encoding='utf-8') as f: for line in f.readlines(): dataMap.append(list(line.strip())) rows = len(dataMap) cols = len(dataMap[0]) # 记录走出人数 count = 0 for x inrange(rows): for y inrange(cols): # 用于记录走过的轨迹,未走过为0,走过为1 paths = [[0]*cols for _ inrange(rows)] dfs(x, y) print(count)
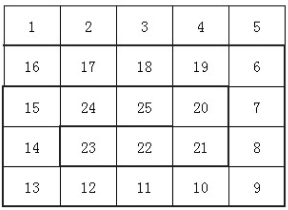
lis = [[0for i inrange(40)] for j inrange(40)] num = 1# 记录当前的数 for i inrange(1, 41): # 层数 for j, k inzip(list(range(i)), list(range(num, num + i))): if i % 2 == 0: # 偶数层 lis[j][i-j-1] = k else: lis[i-j-1][j] = k num += i print(lis[19][19])
f0=1 f1=1 f2=1 for i inrange(3, 20190324): result = (f0 + f1 + f2) % 10000 f0 = f1 f1 = f2 f2 = result print(result)
数位递增的数
题目描述
一个正整数如果任何一个数位不大于右边相邻的数位,则称为一个数位递增的数,例如1135是一个数位递增的数,而1024不是一个数位递增的数。 给定正整数 n,请问在整数 1 至 n 中有多少个数位递增的数?
输入描述
输入的第一行包含一个整数n。
输出描述
输出一行包含一个整数,表示答案。
输入样例
30
输出样例
26
对于 40% 的评测用例,1 <= n <= 1000。 对于 80% 的评测用例,1 <= n <= 100000。 对于所有评测用例,1 <= n <= 1000000。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
n = int(input()) count = 0 for i inrange(1, n+1): num = str(i) iflen(num) == 1: count += 1 else: flag = True for j inrange(len(num) - 1): if num[j] > num[j+1]: flag = False break if flag: count += 1 print(count)
n = int(input()) start = time.perf_counter() #6位数,n一定为偶数 if (n % 2 == 0): s = n // 2 if s <= 27: for i inrange(1, 10): for j inrange(10): if (s - i - j) < 10and (s - i - j) >= 0: print(int(str(i)+str(j)+str(s-i-j)*2+str(j)+str(i))) #5位数,n减去中间那个数一定为偶数 for i inrange(9, -1, -1): if (n - i) % 2 == 0: s = (n - i) // 2 if s <= 18: for j inrange(1, 10): if (s - j) >= 0and (s - j) < 10: print(int(str(j)+str(s-j)+str(i)+str(s-j)+str(j))) end = time.perf_counter() print(end - start)
n = int(input()) arr = [[] for _ inrange(n)] for i inrange(n): arr_ = input().split() for j inrange(n): arr[i].append(int(arr_[j])) # 既然好芯片比坏芯片多,那么我们只需记录每一列0的个数就行了,若个数超过n/2,则此芯片为坏芯片 for j inrange(n): count = 0 for i inrange(n): if arr[i][j] == 0: count += 1 if count > n / 2: continue print(j+1, end=' ')
n = int(input()) # 存放号码 consumer = [] # 统计-1的个数 ans = 0 # 存放结果 res = [] for i inrange(n): data = int(input()) if data != -1: consumer.append(data) # 排序 consumer.sort() else: res.append(consumer[ans]) ans += 1 print(res)
序列计数
题目描述
小明想知道,满足以下条件的正整数序列的数量:
第一项为n;
第二项不超过n;
从第三项开始,每一项小于前两项的差的绝对值。
请计算,对于给定的n,有多少种满足条件的序列。
输入描述
输入一行包含一个整数n。
输出描述
输出一个整数,表示答案。答案可能很大,请输出答案除以10000的余数。
输入样例
4
输出样例
7
样例说明
以下是满足条件的序列: 4 1 4 1 1 4 1 2 4 2 4 2 1 4 3 4 4
对于 20% 的评测用例,1 <= n <= 5; 对于 50% 的评测用例,1 <= n <= 10; 对于 80% 的评测用例,1 <= n <= 100; 对于所有评测用例,1 <= n <= 1000。
nums, result=[], 0 withopen("2020.txt") as f: for line in f.readlines(): nums.append(list(line.strip())) move=[[0, 1],[1, 0],[1, 1]] for x inrange(len(nums)): for y inrange(len(nums[0])): for xx, yy in move: num = str(nums[x][y]) for m inrange(1, 4): x_, y_= x + xx * m, y + yy * m if0 <= x_ < len(nums) and0 <= y_ <len(nums[0]): num += str(nums[x_][y_]) else: break if num == '2020': result += 1 print(result)
count = 0 # 根据对称,只要到根号即可 for i inrange(1, int(float(1200000)**0.5) + 1): if1200000 % i == 0: count += 2 print(count)
长草
题目描述
小明有一块空地,他将这块空地划分为 n 行 m 列的小块,每行和每列的长度都为 1。 小明选了其中的一些小块空地,种上了草,其他小块仍然保持是空地。 这些草长得很快,每个月,草都会向外长出一些,如果一个小块种了草,则它将向自己的上、下、左、右四小块空地扩展,这四小块空地都将变为有草的小块。 请告诉小明,k 个月后空地上哪些地方有草。
输入描述
输入的第一行包含两个整数 n, m。 接下来 n 行,每行包含 m 个字母,表示初始的空地状态,字母之间没有空格。如果为小数点,表示为空地,如果字母为 g,表示种了草。 接下来包含一个整数 k。
输出描述
输出 n 行,每行包含 m 个字母,表示 k 个月后空地的状态。如果为小数点,表示为空地,如果字母为 g,表示长了草。
defgrow(x, y): for offset in R: x1 = x + offset[0] y1 = y + offset[1] if y1 >= 0and y1 < m and x1 >= 0and x1 < n and area[x1][y1] == '.': area[x1][y1] = 'g' flag[x1][y1] = 1
n, m = map(int, input().split()) area = [list(input()) for _ inrange(n)] k = int(input()) # 上下左右 R = [(-1, 0), (0, -1), (1, 0), (0, 1)] # 长草月数 for month inrange(k): # 记录已经生长过的草位置 flag = [[0for _ inrange(m)] for _ inrange(n)] for i inrange(n): for j inrange(m): if area[i][j] == 'g'and flag[i][j] == 0: flag[i][j] = 1 grow(i, j)
装饰珠有 M 种,编号 1 至 M,分别对应 M 种技能,第 i 种装饰珠的等级为 $L_i$,只能镶嵌在等级大于等于 $L_i$ 的装饰孔中。 对第 i 种技能来说,当装备相应技能的装饰珠数量达到 $K_i$个时,会产生$W_i(K_i)$的价值,镶嵌同类技能的数量越多,产生的价值越大,即$W_i(K_{i-1})<W_i(K_i)$。但每个技能都有上限$P_i$(1≤$P_i$≤7),当装备的珠子数量超过$P_i$时,只会产生$W_i(P_i)$的价值。
对于给定的装备和装饰珠数据,求解如何镶嵌装饰珠,使得 6 件装备能得到的总价值达到最大。
输入描述
输入的第 1 至 6 行,包含 6 件装备的描述。其中第i行的第一个整数$N_i$表示第i件装备的装饰孔数量。后面紧接着$N_i$个整数,分别表示该装备上每个装饰孔的等级L(1≤ L ≤4)。 第 7 行包含一个正整数 M,表示装饰珠 (技能) 种类数量。 第 8 至 M + 7 行,每行描述一种装饰珠 (技能) 的情况。每行的前两个整数$L_j$(1≤ $L_j$ ≤4)和$P_j$(1≤ $P_j$ ≤7)分别表示第 j 种装饰珠的等级和上限。接下来$P_j$个整数,其中第 k 个数表示装备该中装饰珠数量为 k 时的价值$W_j(k)$。 其中1 ≤ $N_i$ ≤ 50,1 ≤ M ≤ $10^4$,1 ≤ $W_j(k)$ ≤ $10^4$。
s = input() buttom = int(input()) rows = int(input()) arr = [input() for _ inrange(rows)] res = [] if buttom == 1: for i in arr: if s in i: res.append(i) else: s = s.lower() for i in arr: if s in i.lower(): res.append(i)
#递归搜索, 求该位置出发的最长路径 defdfs(x, y): # 初始化为1 maxHeight = 1 # 该位置周边的四个点 offset = [[-1, 0], [1, 0], [0, -1], [0, 1]] for i in offset: # 下一个搜索点的横坐标 tx = x + i[0] # 下一个搜索点的纵坐标 ty = y + i[1] # 若超出边界,跳过 if tx < 0or tx > R - 1or ty < 0or ty > C - 1: continue # 若不满足高度差,跳过 if arr[tx][ty] >= arr[x][y]: continue # 当前位置出发的最长路径只有两种情况 # 1.找不到满足条件的搜索点为它自身 2.下一个搜索点的最长路径+1 maxHeight = max(maxHeight, dfs(tx, ty) + 1) return maxHeight
#输入 R, C = map(int, input().split()) arr = [list(map(int, input().split())) for _ inrange(R)] # 存放最长路径的结果 res = 0 for x inrange(R): for y inrange(C): res = max(res, dfs(x, y)) print(res)