ConvNeXt:重新设计纯卷积ConvNet
前言
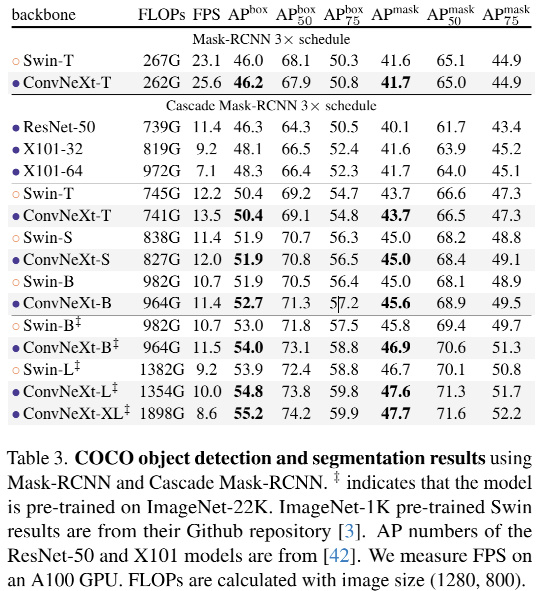
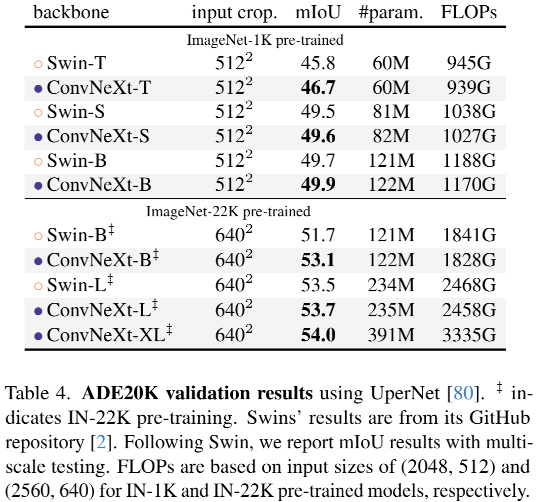
最近看到一篇挺有意思的文章,来自Facebook和加州伯克利团队设计并测试了纯ConvNet所能达到的极限命名为ConvNeXt。ConvNeXt完全由卷积网络构建,在准确性和可扩展性方面ConvNeXt取得了与Transformer具有竞争力的结果,达到87.8% ImageNet top-1 准确率,在COCO检测和ADE20K分割方面优于Swin Transformer,同时保持标准ConvNet的简单性和有效性。
介绍
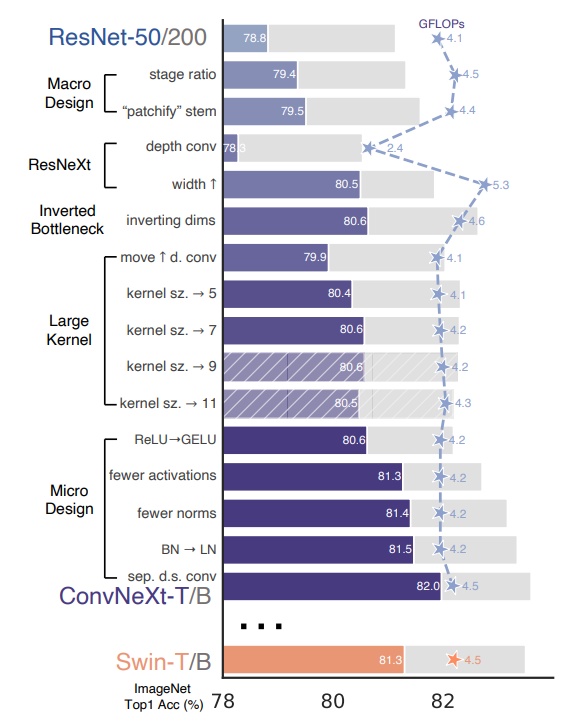
这张图可以说是整篇论文的精华,光看这张图就知道该做什么了😏。
总结为: ① 宏观设计 ② ResNeXt ③ 反转瓶颈 ④ 卷积核大小 ⑤ 各种逐层微设计
内容
就是对Transformer的trick进行梳理和模仿,把ResNet50从76.1一步步干到82.0。个人觉得挺有意思的。
训练策略优化(76.1-78.8)
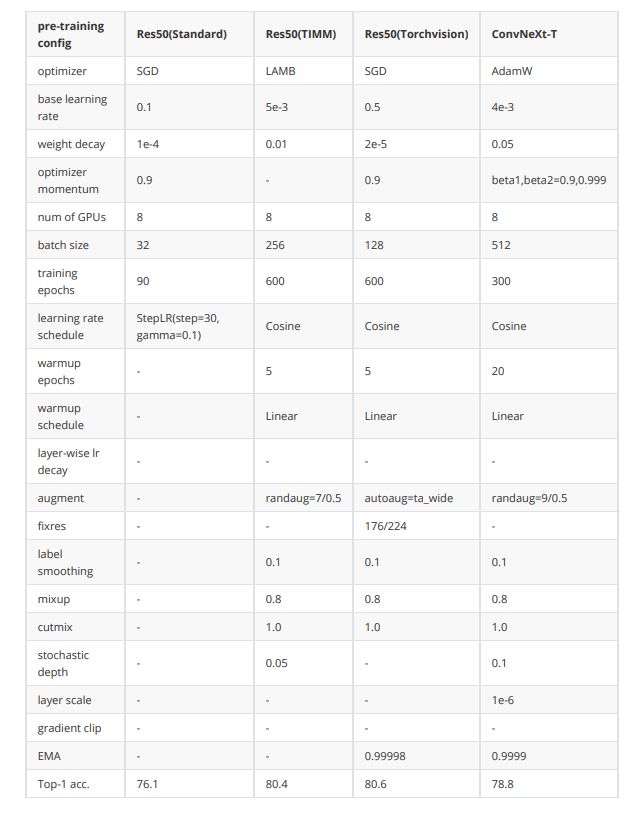
2021年timm和torchvision团队均有工作讲述如何通过优化训练策略来使resnet50性能提升到80以上。本文考虑到跟Swin Transformer的公平对比,训练策略没有完全follow前面的工作,但仍然可以对ResNet50带来提升。
改变stage compute ratio(78.8-79.4)
改变layer0到layer3的block数量比例,由标准的(3,4,6,3)改为Swin-T使用的(3,3,9,3),即1:1:3:1。对于更大的模型,也跟进了Swin所使用的1:1:9:1。
使用Patchify的stem(79.4-79.5)
就是将传统ResNet中stem层使用的一个stride=2的7x7卷积加最大池化层改成patch,用stride=4的4x4卷积来进行stem,使得滑动窗口不再相交,每次只处理一个patch的信息。跟之前有一篇「Patches are all you need」(该文章认为是Patches起的作用,而不是Transformer,在ConvNet中应用了Patches也得到了不错的效果)异曲同工之妙。
1 | # 标准ResNet |
ResNeXt化(79.5-80.5)
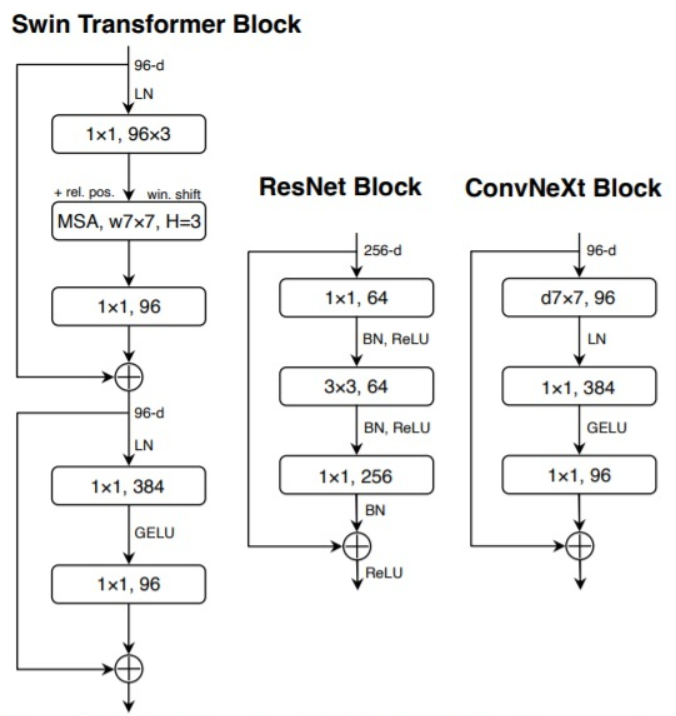
ResNeXt的指导准则是“分更多的组,拓宽width”,因此本文直接使用了depthwise conv,即分组数等于输入通道数。这里,作者发现dw conv由于每个卷积核单独处理一个通道,这种形式跟self-attention机制很相似,都是在单个通道内做空间信息的混合加权。将bottleneck中的3x3卷积替换成dw conv 7×7,再把网络宽度从64提升到96(跟Transformer对齐)。
可以这么理解:注意力模块核心公式就是attention × V,attention是HW×HW矩阵,而V是HW×C矩阵,这个矩阵乘法的权重是通道C共享的,如果换成attention序列长度是1即1×HW,V是HW×C,那么每个输出序列长度是1×C,可以看出自注意力模块是没有跨通道信息聚合的。因此作者认为自注意力层可以和DW Conv等价,用dw conv 7×7替换MSA。
反瓶颈结构(80.5-80.6)
在标准ResNet中使用的bottleneck是(大维度-小维度-大维度)的形式来减小计算量。后来在MobileNetV2中提出了inverted bottleneck结构,采用(小维度-大维度-小维度)形式,认为这样能让信息在不同维度特征空间之间转换时避免压缩维度带来的信息损失,后来在Transformer的MLP中也使用了类似的结构,中间层全连接层维度数是两端的4倍。
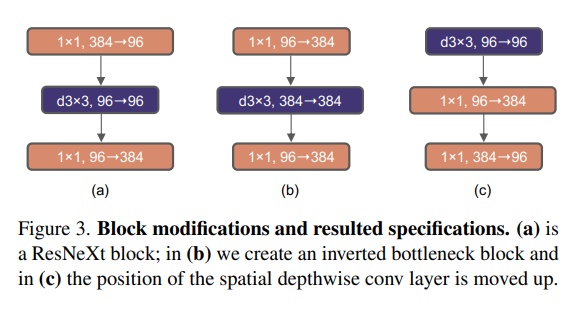
大卷积核(80.6-80.6)
由于Swin-T中使用了7x7卷积核,这一步主要是为了对齐比较。又因为inverted bottleneck放大了中间卷积层的缘故,直接替换会导致参数量增大,因而作者把dw conv的位置进行了调整,放到了反瓶颈的开头。最终结果相近,说明在7x7在相同参数量下效果是一致的。(其实就是作者认为自注意力层可以和DW Conv等价,用dw conv 7×7替换MSA)
用GELU替换ReLU(80.6-80.6)
主要是为了对齐比较(因为Transformer用了GELU),并没有带来提升。
减少激活层数量(80.6-81.3)
由于Transformer中只使用了一个激活层,因此在设计上进行了效仿,结果发现只在block中的两个1x1卷积之间使用一层激活层,其他地方不适用,反而带来了0.7个点的提升。这说明太频繁地做非线性投影对于网络特征的信息传递实际上是有害的。
减少归一化层数量(81.3-81.4)
基于跟减少激活层相同的逻辑,由于Transformer中BN层很少,本文也只保留了1x1卷积之前的一层BN,而两个1x1卷积层之间甚至没有使用归一化层,只做了非线性投影。
用LN替换BN(81.4-81.5)
由于Transformer中使用了LN,且一些研究发现BN会对网络性能带来一些负面影响,本文为了对齐,将所有的BN替换为LN。结果玄学起来了,正常来说BN适用于图像,LN适用于序列,LN照理来说会掉点,这里反而提升了😨。估摸着是不是因为前面减少了归一化层数量,只在DW 7×7后做归一,而DW又近似于注意力效果,因此就像LN适合Transformer一样,LN也对其有提升?
单独的下采样层(81.5-82.0)
标准ResNet的下采样层通常是stride=2的3x3卷积,对于有残差结构的block则在短路连接中使用stride=2的1x1卷积,这使得CNN的下采样层基本与其他层保持了相似的计算策略。而Swin-T中的下采样层是单独的,因此本文用stride=2的2x2卷积进行模拟。又因为这样会使训练不稳定,因此每个下采样层后面增加了LN来稳定训练。
1 | self.downsample_layers = nn.ModuleList() |
网络结构
对以上内容进行整合,最终得到了单个block的设计及代码:
1 | class Block(nn.Module): |
通过代码可以注意到,以上Block中两层1x1卷积是用全连接层来实现的,按照作者的说法,这样会比使用卷积层略快。(不过作者是在GPU上进行的实验,有人测试在CPU上还是使用1x1卷积层的速度更快,可以根据需要替换)
实验
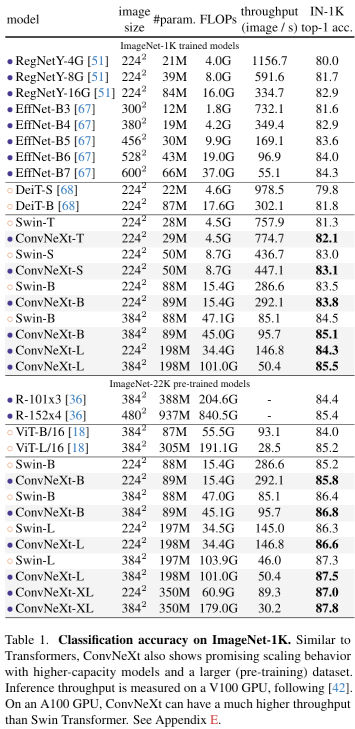
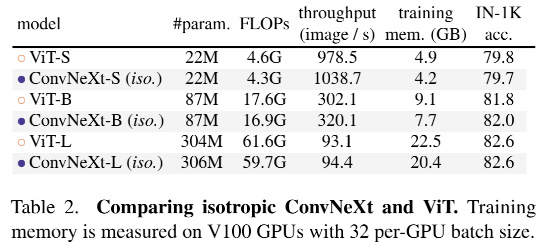
基于前述ConvNeXt架构,构建了ConvNeXt-T/S/B/L对标Swin-T/S/B/L。此外,还构建了一个更大的ConvNeXt-XL以进一步测试ConvNeXt的缩放性。
- ConvNeXt-T:C = (96, 192, 384, 768),B = (3, 3, 9, 3)
- ConvNeXt-s:C = (96, 192, 384, 768),B = (3, 3, 27, 3)
- ConvNeXt-B:C = (128, 256, 512, 1024),B = (3, 3, 27, 3)
- ConvNeXt-L:C = (192, 384, 768, 1536),B = (3, 3, 27, 3)
- ConvNeXt-XL:C = (256, 512, 1024, 2048),B = (3, 3, 27, 3)
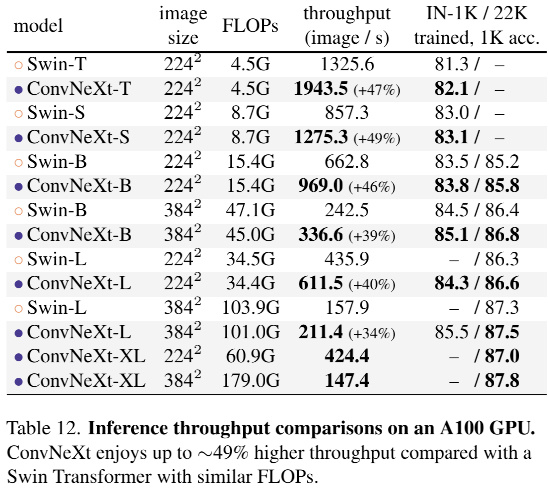
总结
虽然本篇文章各种trick堆叠,但网络本身结构还算简单,通过与Transformer对其,来说明ConvNet还是能打(Transformer给👴爬!),个人还是比较喜欢的。至少比起Transformer来说对于穷人比较友好,卷积网络也不容易出现难收敛的情况。FLOPs凑合,param在分类网络中稍微有点大,应该是由于每个block都使用7×7大卷积,block之间用全连接的关系,但至少比起Transformer还是可以跑得动的😋。