加速pytorch数据读取
介绍
prefetch_generator是第三方对原本的DataLoader进行重写的函数包,它将任意生成器转换为后台thead生成器,在并行后台thead中预取多批数据。
如果有一个计算量很大的进程(CPU或GPU),在生成器消耗其他资源(磁盘IO/从数据库加载/如果有未使用的内核,则有更多CPU)的同时迭代处理生成器中的小批量,则这非常有用。
默认情况下,这两个进程将不断等待对方完成。如果让生成器在预取模式下工作,它们将并行工作,可能会节省GPU时间。
安装
1 | pip install prefetch_generator |
使用
之前加载数据集的正确方式是使用torch.utils.data.DataLoader,现在我们只要利用这个库,新建个DataLoaderX类继承DataLoader并重写__iter__方法即可
1 | # 新建DataLoaderX类 |
然后用 DataLoaderX 替换原本的 DataLoader。
1 | train_dataset = MyDataset(".........") |
提速原因
原本Pytorch默认的DataLoader会创建一些worker线程来预读取新的数据,但是除非这些线程的数据全部都被清空,这些线程才会读下一批数据。使用prefetch_generator在后台加载下一batch的数据,我们可以保证线程不会等待,每个线程都总有至少一个数据在加载。
效果
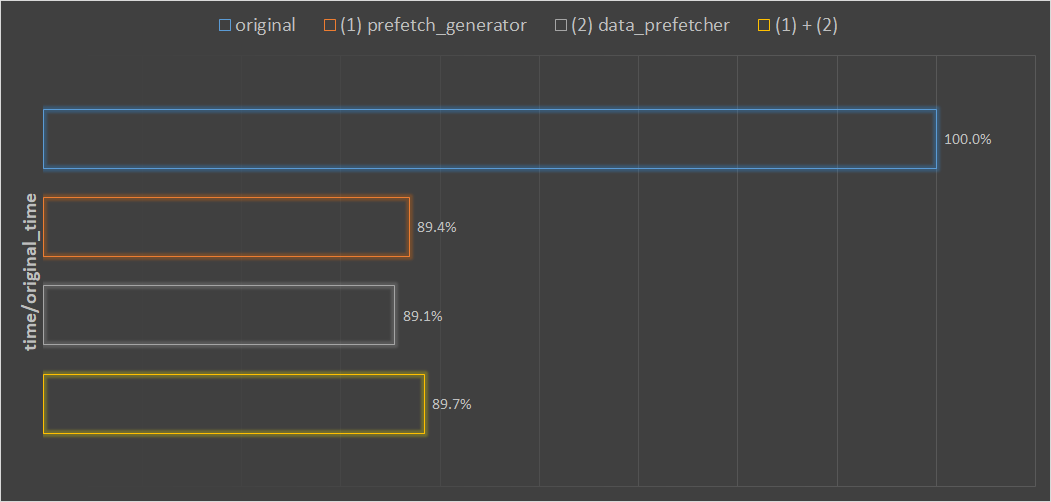
在 hdd 硬盘上,用同样的参数、同样的数据,分别用不同的优化方法,训练两个epoch,记录训练的时间。
优化方法分别是:
original:默认 dataloader,不优化(1)prefetcher_generator:只用 prefetcher_generator 库优化(2)data_prefetcher:只用 data_prefetcher 优化(1)+(2):同时用prefetcher_generator和data_prefetcher优化
最后将得到的时间,除以不优化时的训练时间。
从图中可以观察到:
- (1) 和 (2) 两种优化方法都差不多有 10% 左右的训练时间的缩短;
- (1) (2) 同时使用,并没有进一步缩短训练时间,反而不如只使用一种优化方法。
https://qiyuan-z.github.io/2020/09/13/%E5%8A%A0%E9%80%9Fpytorch%E6%95%B0%E6%8D%AE%E8%AF%BB%E5%8F%96/
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yuan!
相关推荐

评论