SSD算法的改进版Rainbow SSD
前言
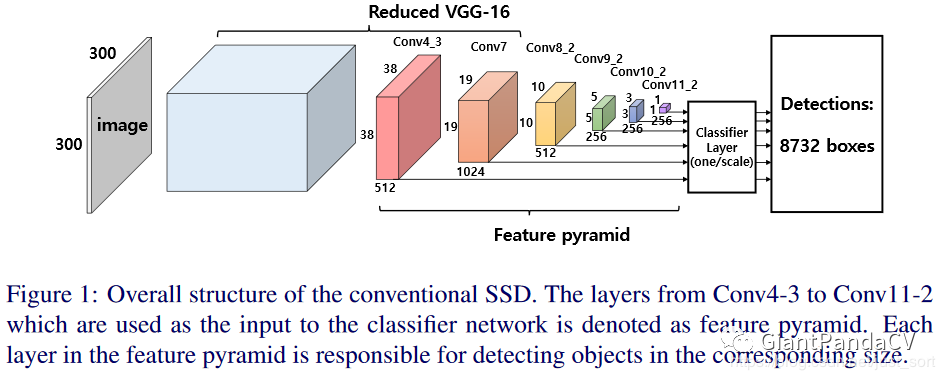
这是BMVC 2017的一个SSD的改进算法R-SSD。这里先看一下SSD的网络结构图吧。
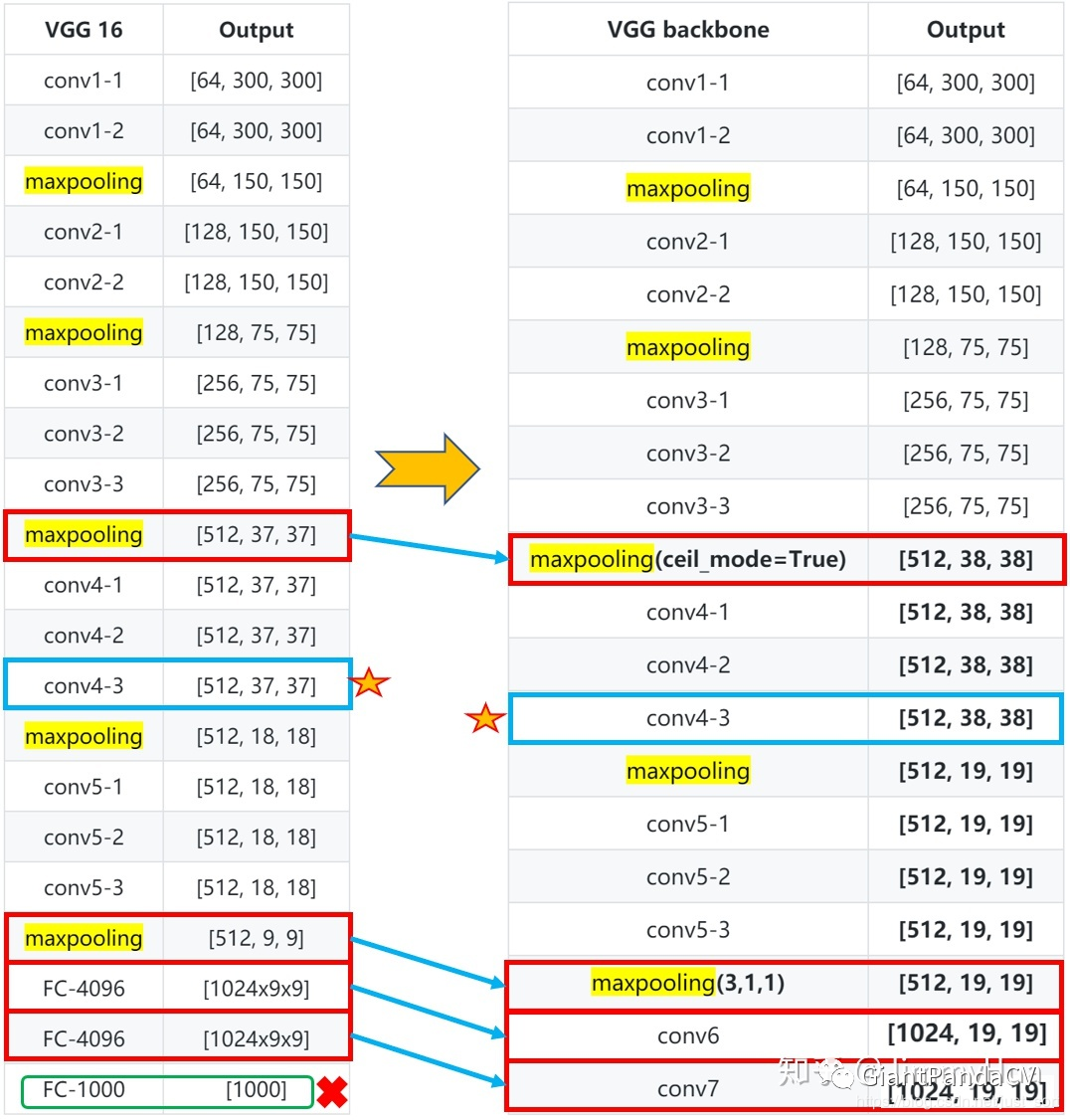
带有特征图维度信息的更清晰的骨干网络和VGG16的对比图如下:
出发点
一般来说,深度神经网络的特征图数量越多,我们获得的性能一般会更好。但是这并不一定代表着简单的增加特征图的数量就能使得效果变好,这一点在实验部分有说明。这篇论文在SSD的基础上并没有改变BackBone网络,即还是应用稍加修改的VGG16为BackBone。这篇论文的贡献是提出了新的特征融合方式来提升了SSD的效果,这一改进使得SSD可以充分利用特征,虽然速度稍慢于原始的SSD算法,但mAP却获得了较大的提升。
介绍
传统的SSD算法通过不同层的特征来做检测,使得其对尺度变化有较好的鲁棒性,在速度和精度的Trade-Off上也做得比较好,但是SSD有2个明显的问题:
- 在SSD中,不同层的特征图都是独立作为分类网络的输入,因此容易出现相同物体被不同大小的框同时检测出来的情况。
- 对小目标的检测效果比较差,当然这也是大多数目标检测算法的通病了。
因此,这篇算法也主要从这两点出发来改进传统的SSD算法。首先,本文利用分类网络增加不同层之间的特征图联系,减少重复框的出现。然后,增加特征金字塔中特征图的个数,使得网络可以检测更多的小目标。下面的Figure5(a),(c)分别展示了SSD算法出现的上述2个问题,而Figure5(b),(d)分别展示了本文提出的R-SSD算法的改进效果图。

Rainbow SSD核心原理
下面的Figure3展示了几种不同的特征融合方式。
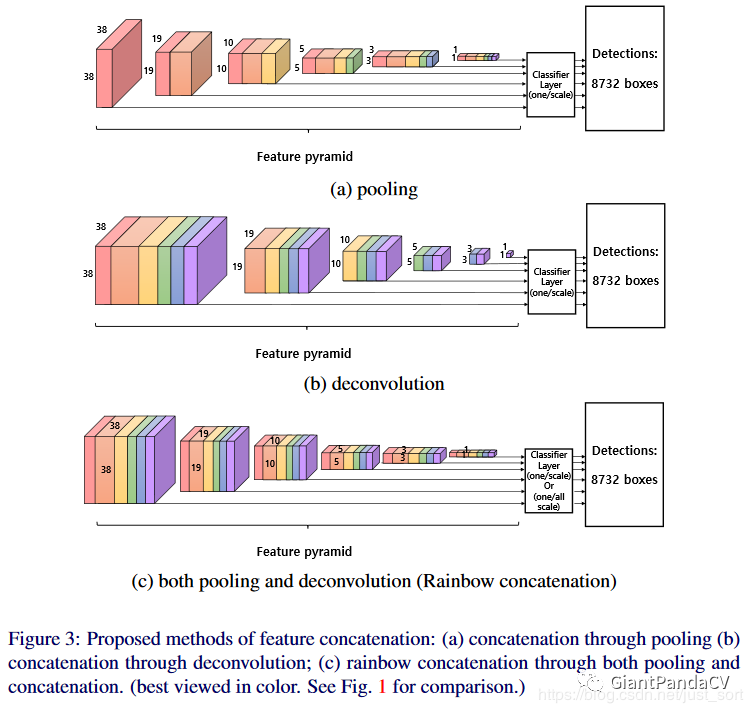
我们来尝试解析一下这些图都表示什么?
Figure3(a):这表示使用pooling方式的特征图融合,我们可以看到(a)最左边的38 x 38的特征图将其做一个pooling之后和接下来那个19 x 19的特征图进行concate,获得了那个一个红加一个橙的特征图。后面同理。Figure3(b):这表示使用反卷积的方式进行特征融合,注意这里是从右边的1 x 1的紫色特征图往左做concate,因为反卷积是升维,所以从右至左。Figure3(c):表示「同时使用Pooling和反卷积做特征融合。」 这个结构就是本文的Radinbow SSD的核心了,即同时从左至右(pooling,concate)和从右至左(deconvolution,concate)。
可以看到Rainbow SSD里融合后的特征图色彩很像彩虹,这大概就是这个名字的由来了。另外一个关键点是「在做concate之前都会对特征图做一个normalization操作,因为不同层的特征图的scale是不同的,本文中的normalization方式采用Batch Normalization。」
由于Figure3中的特征融合方式比较特殊,这就导致融合后的每一层特征图的个数都是相同的,都为2816,因此可以共享部分参数,具体来说就是default boxes的参数共享
下面的Table1展示了和SSD算法中的default boxes的数量对比。

实验结果
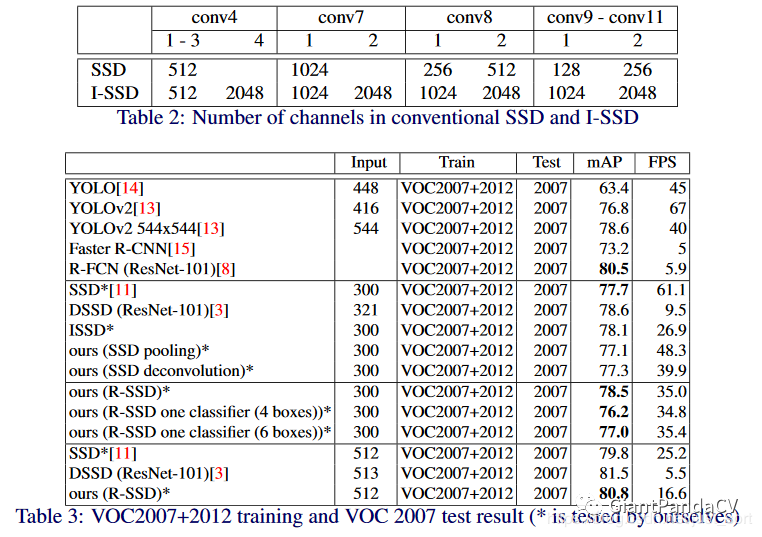
下面的Table3展示了不同的实验对比结果,同时Table2表示只在原始的SSD基础上增加不同特征层数量的「I-SSD」算法。通过Table3的实验结果可以看出虽然ISSD也获得了不错的效果,但是它的FPS却偏低。本文的Rainbow SSD效果和FPS都表现不错。R-FCN虽然效果不错,但是速度上不占优势。
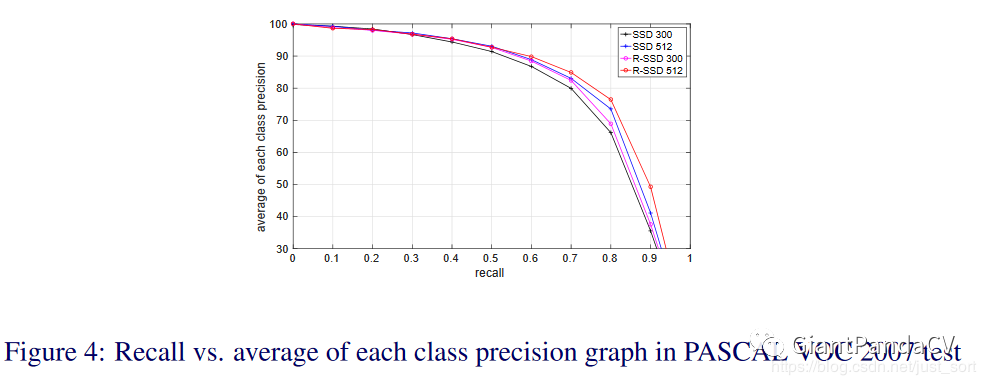
下面的Figure4展示了在VOC 2007 test上的PR曲线。
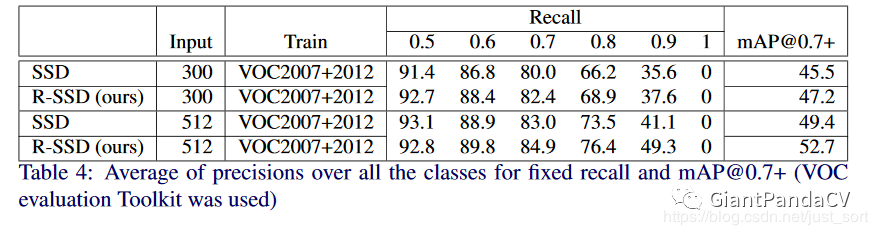
下面的Table4则展示了AP和mAP的详细对比。
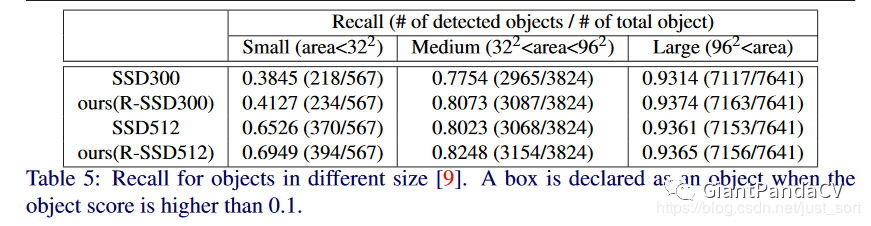
下面的Table5展示了不同Scale的目标召回率的对比,可以看到Rainbow SSD对小目标检测的召回率提升更加明显。
总结
这篇论文提出了一种rainbow concatenation方式来组合特征,在增加不同层之间特征图关系的同时也增加了特征图的个数。「这种融合方式不仅解决了传统SSD算法存在的重复框问题,同时一定程度上解决了小目标的检测问题。」

