RetinaNet(引入Focal Loss)
前言
今天来介绍一下目标检测算法中RetinaNet,这篇论文是CVPR2018的作品,Kaiming He大神也是作者之一,同时这篇论文提出的Focal Loss也对工程上训练更好的目标检测模型做出了很大贡献,论文地址为:https://arxiv.org/pdf/1708.02002.pdf
研究背景
前面介绍了一些One-Stage目标检测算法和Two-Stage目标检测算法,这些算法在精度和速度上都各有特点,现在画个图总结一下之前介绍的各种算法的速度和精度:

可以看到One-Stage算法的精度相对于Two_Stage偏低,然后作者把这种问题的原因归结于正负类别不平衡(简单难分类别不平衡)。因此论文通过重新设计标准的交叉熵损失来解决这种难易样本不平衡的问题,即文章的核心Focal Loss。结合了Focal Loss的One-Stage的目标检测器被称为RetinaNet,该检测器在COCO数据集上MAP值可以和FPN(特征金字塔目标检测器)和MaskRCNN接近。
一些问题
什么是hard/esay postive/negtive example
网上找到一张图解释在目标检测任务的一张图中什么是hard/easy postive/negtive example。
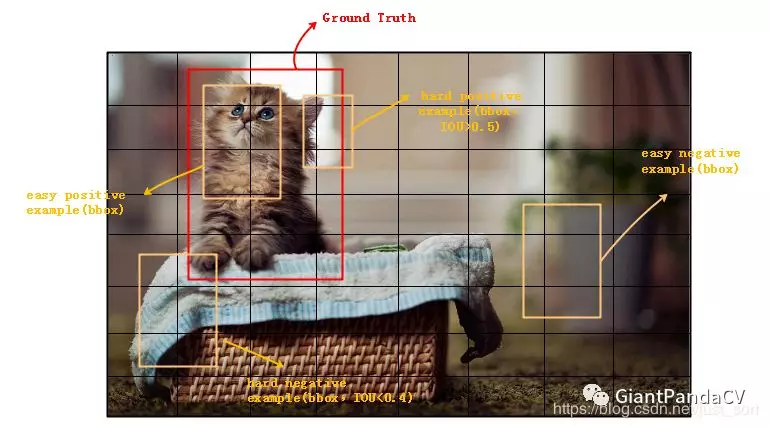
候选框可以分成postive/negtive两类。当bbox(由anchor加上偏移量得到)与ground truth间的IOU大于我们设置的阈值(一般取0.5)时,会认为该bbox属于positive example,如果IOU小于下门限就认为该bbox属于negative example。
为什么One-Stage检测算法精度偏低
论文认为One-Stage算法准确度低是由于类别失衡引起的。因为在一张普通图片中,目标的所占的比例远远小于背景所占的比例,所以两类候选框例子中以negtive example为主。这就导致了:
- (1)针对所有的negtive example,数量过多造成它的loss太大,以至于主导了损失函数,不利于收敛。
- (2)针对单个negtive example来说,大多数的negative example不在前景和背景的过渡区域上,分类很明确(这种易分类的negative称为easy negative),训练时对应的背景类score会很大,换句话说就是单个example的loss很小,反向计算时梯度小。梯度小造成easy negative example对参数的收敛作用很有限,我们更需要loss大的对参数收敛影响也更大的example,即hard positive/negative example。
因此如果One-Stage算法如果无脑的将所有bbox拿去做分类损失,因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。这就导致分类器训练失败了,自然检测精度就偏低了。对于YOLO和SSD来讲,他们也确实没有无脑将所有的bbox拿去做分类损失,如在SSD中利用Hard-Negtive-Mining的方式将正负样本的比例控制在1:3,YOLO通过损失函数中权重惩罚的方式增大正样本对损失函数的影响等。但它们虽然可以处理第1个问题,但对于第2个问题就无能为了,这也是Focal Loss出现的原因。
Faster-RCNN为什么精度更高
Faster-RCNN在FPN阶段会根据前景分数提出最可能是前景的example,这就会滤除大量背景概率高的easy negtive样本,这便解决了上面提出的第2个问题。同时,在生成样本给ROIPooling层的时候,会据IOU的大小来调整positive和negative example的比例,比如设置成1:3,这样防止了negative过多的情况(同时防止了easy negative和hard negative),就解决了前面的第1个问题。因此,相对于One-Stage检测器,Faster-RCNN的精度更高。
Focal Loss
论文引入了Focal Loss来解决难易样本数量不平衡。One-Stage的模板检测器通常会产生10k数量级的框,但只有极少数是正样本,正负样本数量非常不平衡。我们在计算分类的时候常用的损失——交叉熵的公式如下:
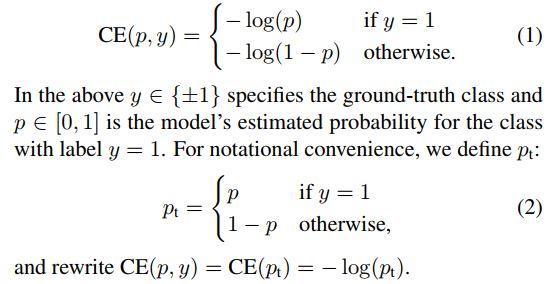
为了解决正负样本数量不平衡的问题,我们经常在交叉熵损失前面加一个参数$\alpha$,即:
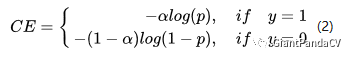

虽然$\alpha$平衡了正负样本的数量,但实际上,目标检测中大量的候选目标都是易分样本。这些样本的损失很低,但是由于数量极不平衡,易分样本的数量相对来讲太多,最终主导了总的损失。
因此,这篇论文认为易分样本(即,置信度高的样本)对模型的提升效果非常小,模型应该主要关注与那些难分样本 。所以Focal Loss横空出世了。一个简单的想法就是只要我们将高置信度(p)样本的损失降低一些就好了吧?也即是下面的公式:
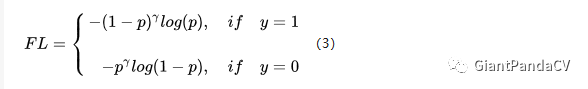

我们取$\gamma$等于2来只管感受一下,如果$p=0.9$,那么,$(1-0.9)^{2}=0.001$,损失降低了1000倍。从中,我们易看出focal loss所加的指数式系数可对正负样本对loss的贡献自动调节。当某样本类别比较明确些,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测准度。
最终Focal Loss还结合了公式(2),这很好理解,公式(3)解决了难易样本的不平衡,公式(2)解决了正负样本的不平衡,将公式(2)与(3)结合使用,同时解决正负难易2个问题!所以最终Focal Loss的形式如下:
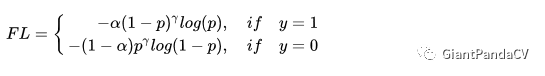
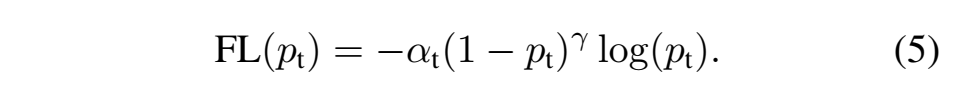
下面这张图展示了Focal Loss取不同的$\gamma$时的损失函数下降。
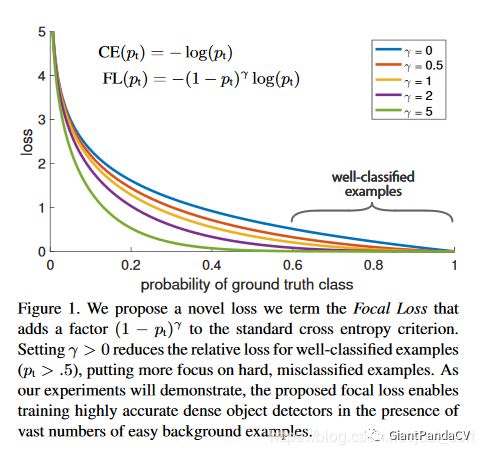
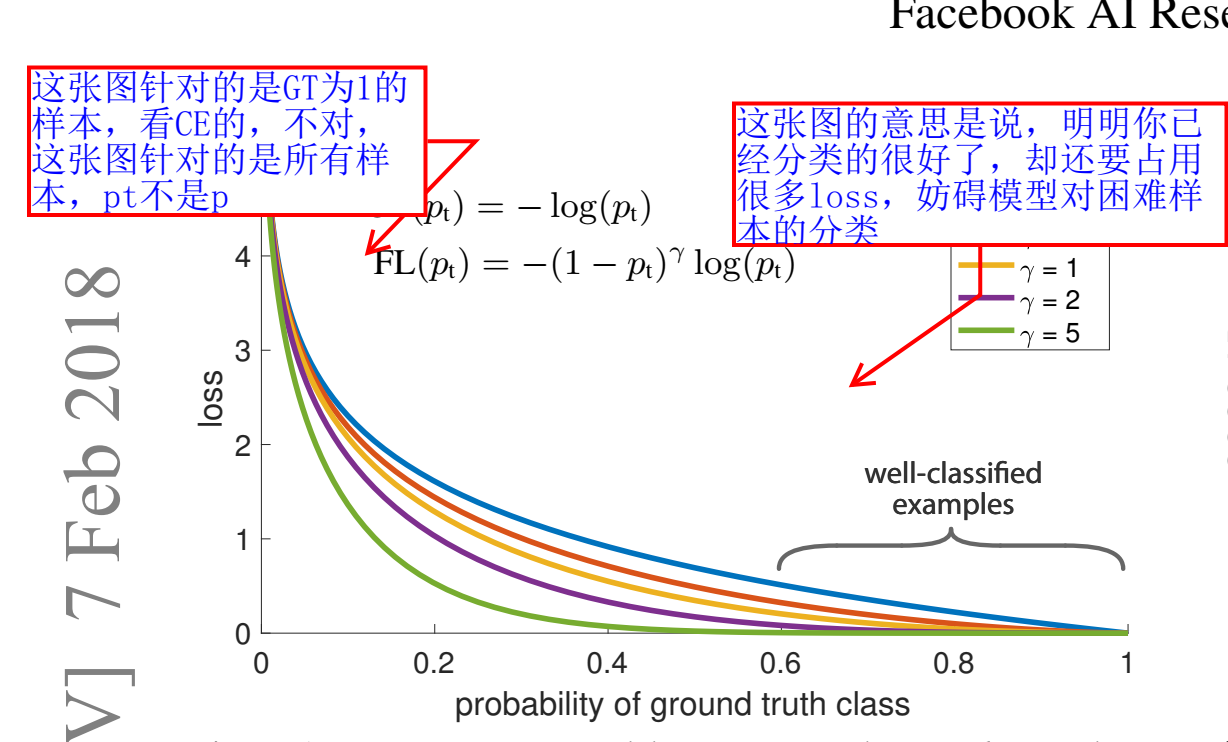
实验结果展示,当$\gamma=2$,$\alpha=0.25$时,效果最好,这样损失函数训练的过程中关注的样本优先级就是正难>负难>正易>负易了。
RetinaNet
说完了Focal Loss就回到文章RetinaNet,Focal Loss与ResNet-101-FPN backbone结合就构成了RetinaNet(one-stage检测器),RetinaNet在COCO test-dev上达到39.1mAP,速度为5FPS。下图展示了RetinaNet的网络结构:
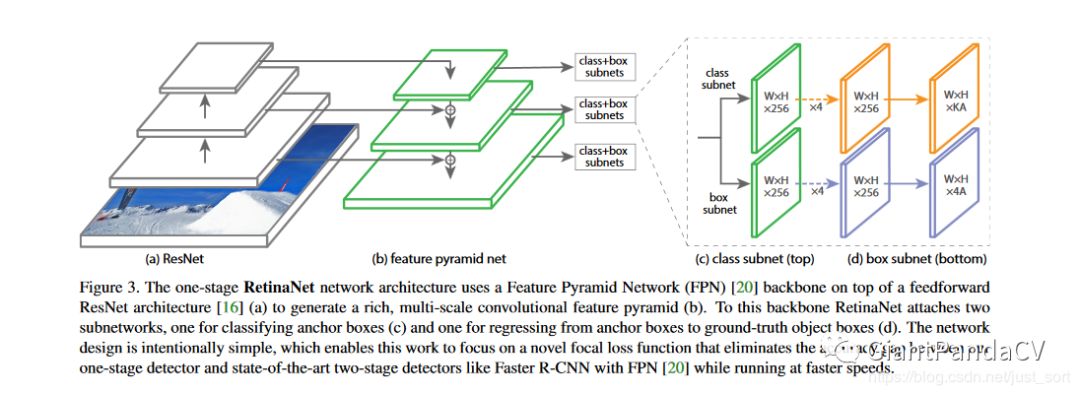
训练RetinaNet时有几个值得注意的关键点:
- 训练时FPN每一级的所有example都被用于计算Focal Loss,loss值加到一起用来训练。
- 测试时FPN每一级只选取score最大的1000个example来做nms。
- 整个结构不同层的head部分(上图中的c和d部分)共享参数,但分类和回归分支间的参数不共享。
- 分类分支的最后一级卷积的bias初始化成-log((1-π)/π)。这里π被指定在训练开始时,所有的anchor都需要被标注为带有π置信率的前景。这里取π=0.01,是为了防止在训练的第一个周期大量的背景anchors生成一个巨大的不稳定的loss值。
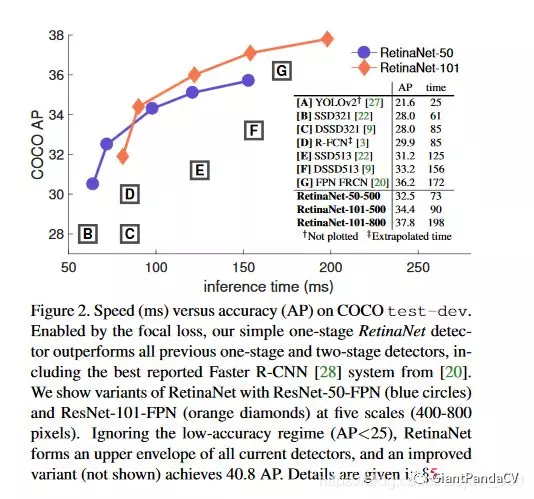
RetinaNet和当时流行的检测算法速度和精度对比如下,可以看到从速度和精度都完成了对其他算法的压制:
实验
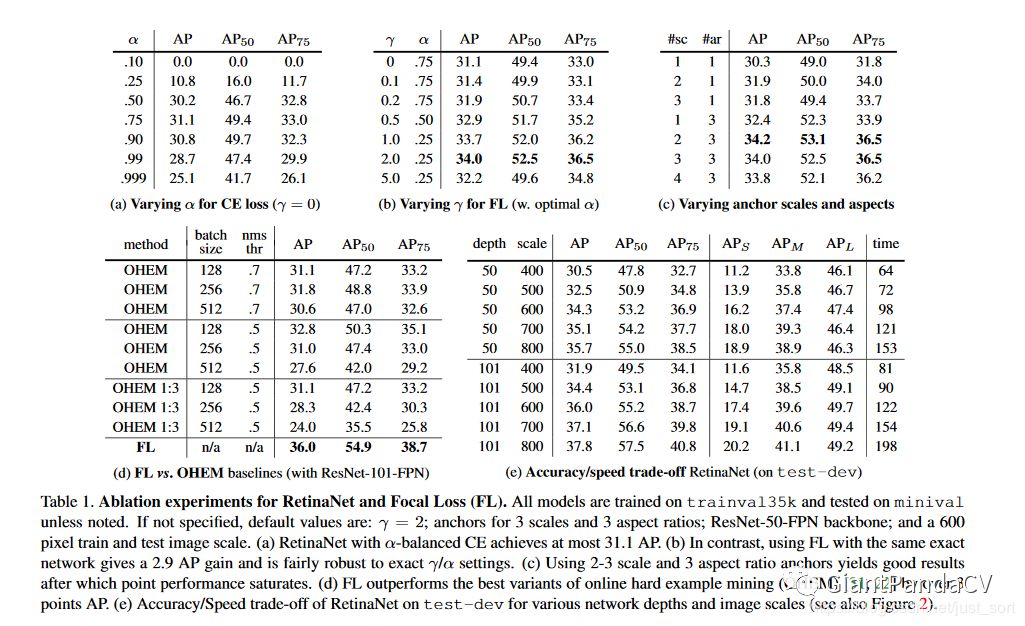
Table1是关于RetinaNet和Focal Loss的一些实验结果。其中(a)是在交叉熵的基础上加上参数$\alpha$,$\alpha=0.5$就表示传统的交叉熵,可以看出当$\alpha=0.75$的时候效果最好,AP值提升了0.9。(b)是对比不同的参数$\gamma$和$\alpha$的实验结果,可以看出随着$\gamma$的增加,AP提升比较明显。(c)是anchor对AP值的影响。(d)是通过和OHEM的对比可以看出最好的Focal Loss比最好的OHEM提高了3.2AP。这里OHEM1:3表示在通过OHEM得到的minibatch上强制positive和negative样本的比例为1:3,通过对比可以看出这种强制的操作并没有提升AP。(e)加入了运算时间的对比,可以和前面的Figure2结合起来看,速度方面也有优势。Table2表示RetinaNet和One-Stage检测器的比较,可以看到RetinaNet也是毫不顺色的。
代码实现
keras版本:https://github.com/fizyr/keras-retinanet
pytorch版本: https://github.com/yhenon/pytorch-retinanet
caffe-focal loss: https://github.com/chuanqi305/FocalLoss

