YOLOv3及YOLOv3-Tiny
算法原理
YOLOv3应该是现在YOLO系列应用的最广泛的算法了,基本就很少有人做工程还用V2了。而YOLOv3的算法原理也很简单,就引入了2个东西,一个是残差模型,一个是FPN架构。
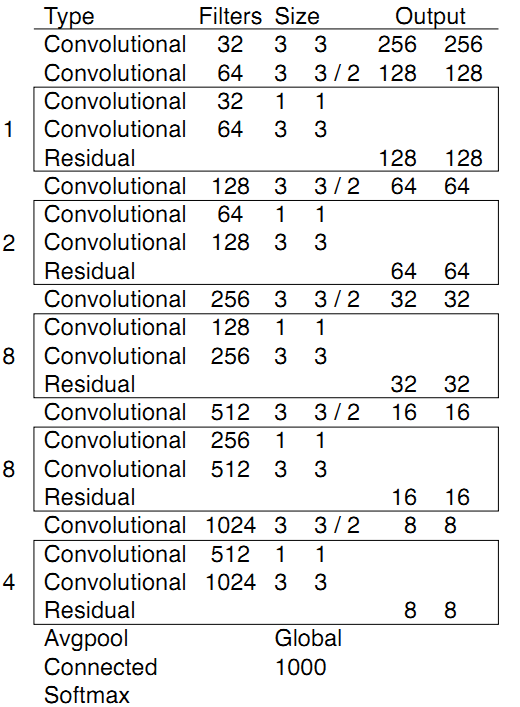
残差模型Darknet-53
YOLOv3在YOLOv2提出的Darknet-19的基础上引入了残差模块,并进一步加深了网络,改进后的网络有53个卷积层,命名为Darknet-53,网络结构如下:
同时为了说明Darknet-53的有效性,作者给出了在TitanX上,使用相同的条件将256 x 256的图片分别输入到以Darknet-19,Resnet-101,以及Resnet-152以及Darknet-53为基础网络的分类模型总,实验结果如下表:
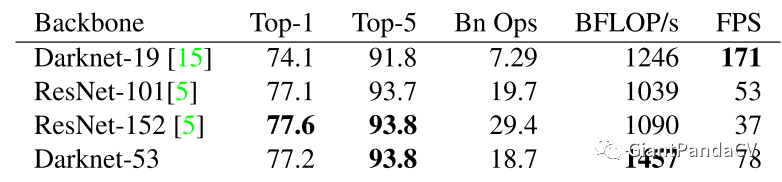
从结果来看,Darknet-53比ResNet-101的性能更好,而且速度是其1.5倍,Darknet-53与ResNet-152性能相似但速度几乎是其2倍。同时,Darknet-53相比于其它网络结构实现了每秒最高的浮点数计算量,说明其网络结构可以更好的利用GPU。
YOLOV3结构
一张非常详细的结构图,其中YOLOv3有三个输出,维度分别是: (batchsize, 52,52,75 ) (batchsize, 26,26,75 ) (batchsize, 13,13,75 )这里的75代表的$3 \times(20+5)$,其中20代表的是COCO数据集目标类别数,5代表的是每个目标预测框的$t_{x}, t_{y}, t_{w}, t_{h}, t_{o}$,3代表的是某一个特征图的Anchor,也即先验框的数目。所以YOLOv3一共有9个Anchor,不过被平均分在了3个特征层中,这也实现了多尺度检测。
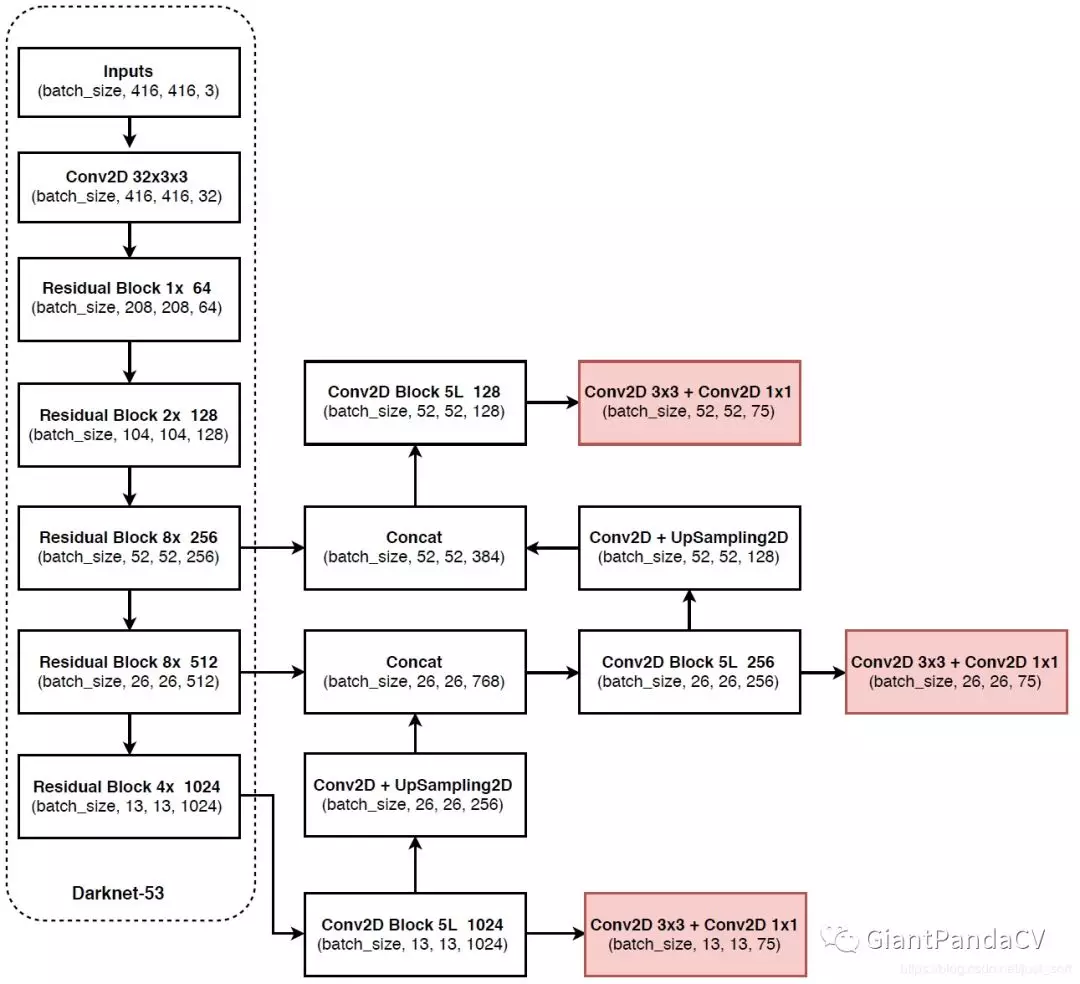
多尺度检测
总结一下,YOLOv3借鉴了FPN的思想,从不同尺度提取特征。相比YOLOv2,YOLOv3提取最后3层特征图,不仅在每个特征图上分别独立做预测,同时通过将小特征图上采样到与大的特征图相同大小,然后与大的特征图拼接做进一步预测。用维度聚类的思想聚类出9种尺度的anchor box,将9种尺度的anchor box均匀的分配给3种尺度的特征图。
补充:YOLOv3-Tiny
或许对于速度要求比较高的项目,YOLOV3-tiny才是我们的首要选择,这个网络的原理不用多说了,就是在YOLOv3的基础上去掉了一些特征层,只保留了2个独立预测分支,具体的结构图如下:
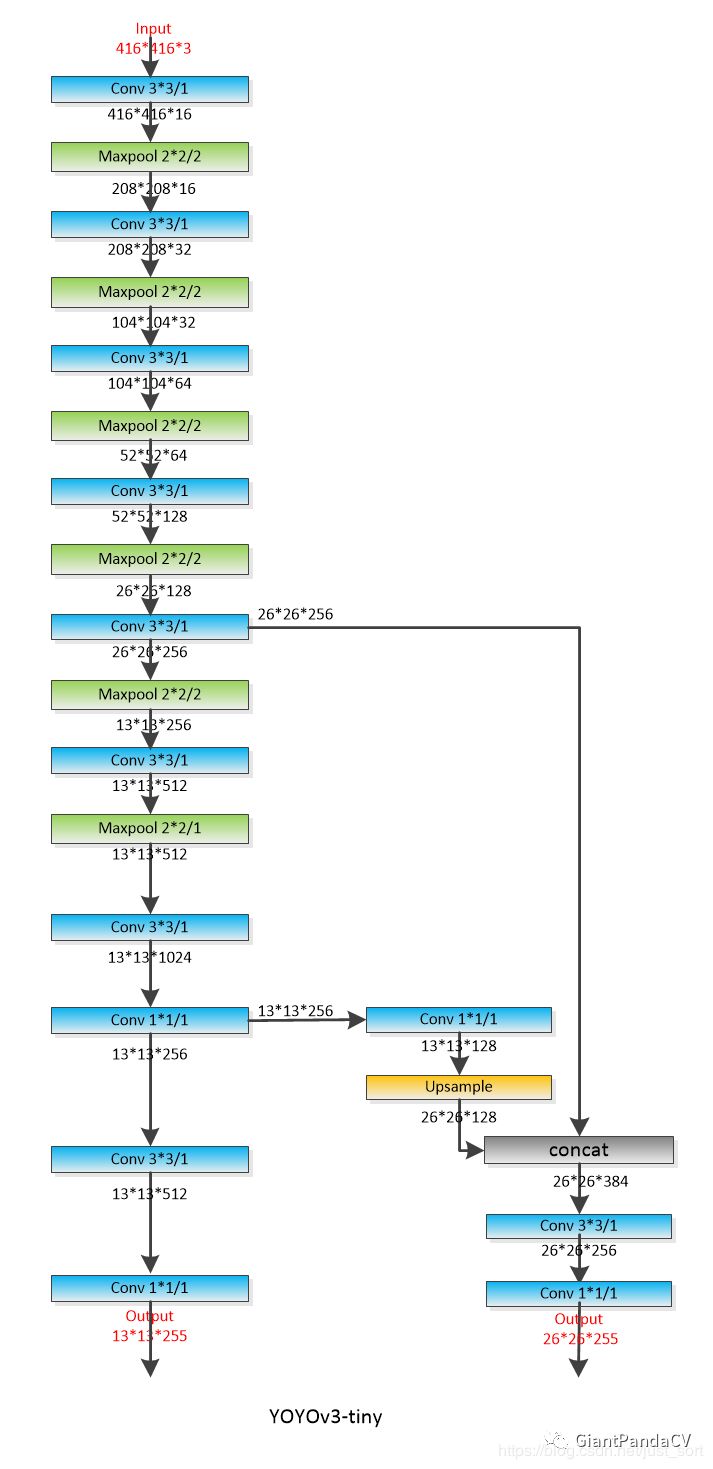
这个是工程下更加常用的。

