AlexeyAB DarkNet数据结构解析 | 字数总计: 3.1k | 阅读时长: 11分钟 | 阅读量:
基础数据结构 为了解析网络配置参数,DarkNet 中定义了三个关键的数据结构类型。list类型变量保存所有的网络参数, section类型变量保存的是网络中每一层的网络类型和参数, 其中的参数又是使用list类型来表示。kvp键值对类型用来保存解析后的参数变量和参数值。
list类型定义在src/list.h中,代码如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 typedef struct node { void *val; struct node *next ; struct node *prev ; } node; typedef struct list { int size; node *front; node *back; } list;
section 类型定义在src/parser.c文件中,代码如下: 1 2 3 4 5 typedef struct { char *type; list *options; }section;
kvp 键值对类型定义在src/option_list.h文件中,具体定义如下: 1 2 3 4 5 6 typedef struct { char *key; char *val; int used; } kvp;
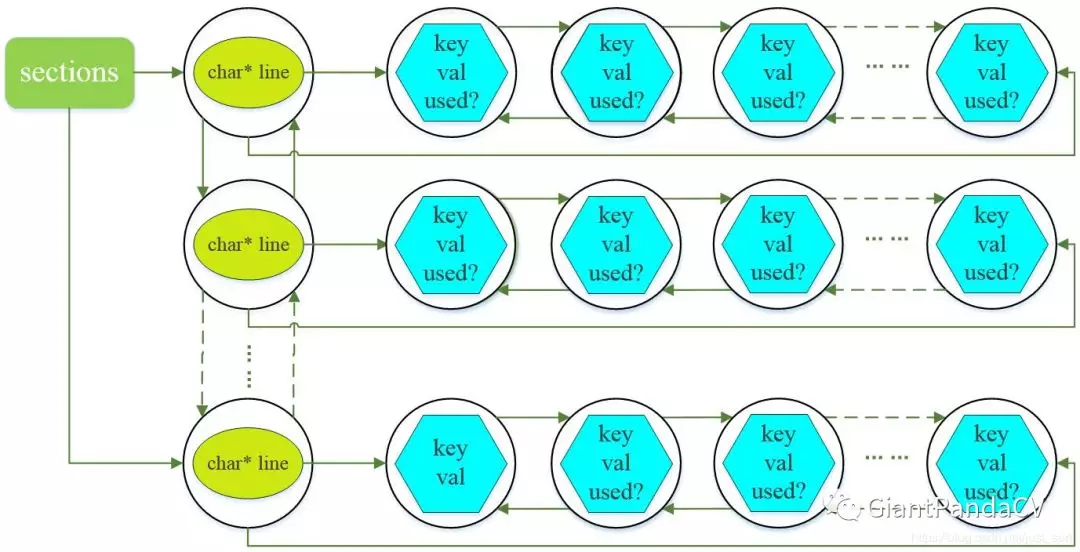
在Darknet的网络配置文件(.cfg结尾)中,以[开头的行被称为一个段(section)。所有的网络配置参数保存在list类型变量中,list中有很多的section节点,每个section中又有一个保存层参数的小list,整体上出现了一种大链挂小链的结构。大链的每个节点为section,每个section中包含的参数保存在小链中,小链的节点值的数据类型为kvp键值对,这里有个图片可以解释这种结构。
我们来大概解释下该参数网,首先创建一个list,取名sections,记录一共有多少个section(一个section存储了某一网络层所需参数);然后创建一个node,该node的void类型的指针指向一个新创建的section;该section的char类型指针指向.cfg文件中的某一行(line),然后将该section的list指针指向一个新创建的node,该node的void指针指向一个kvp结构体,kvp结构体中的key就是.cfg文件中的关键字(如:batch,subdivisions等),val就是对应的值;如此循环就形成了上述的参数网络图。
解析并保存网络参数到链表中 读取配置文件由src/parser.c中的read_cfg()函数实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 list *read_cfg (char *filename) FILE *file = fopen (filename, "r" ); if (file == 0 ) file_error (filename); char *line; int nu = 0 ; list *sections = make_list (); section *current = 0 ; while ((line=fgetl (file)) != 0 ){ ++ nu; strip (line); switch 0 ]){ case '[' : current = (section*)xmalloc (sizeof list_insert (sections, current); current->options = make_list (); current->type = line; break ; case '\0' : case '#' : case ';' : free (line); break ; default : if (!read_option (line, current->options)){ fprintf (stderr, "Config file error line %d, could parse: %s\n" , nu, line); free (line); } break ; } } fclose (file); return sections; }
链表的插入操作 保存section和每个参数组成的键值对时使用的是list_insert()函数, 前面提到了参数保存的结构其实是大链(节点为section)上边挂着很多小链(每个section节点的各个参数)。list_insert()函数实现了链表插入操作,该函数定义在src/list.c文件中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void list_insert (list *l, void *val) node* newnode = (node*)xmalloc (sizeof newnode->val = val; newnode->next = 0 ; if (!l->back){ l->front = newnode; newnode->prev = 0 ; }else { l->back->next = newnode; newnode->prev = l->back; } l->back = newnode; ++l->size; }
可以看到, 插入的数据都会被重新包装在一个新的node : 变量new中,然后再将这个节点插入到链表中。网络结构解析到链表中后还不能直接使用, 因为想使用任意一个参数都不得不每次去遍历整个链表, 这样就会导致程序效率变低, 所以最好的办法是将其保存到一个结构体变量中, 使用的时候按照成员进行访问。复杂度从$O(n)->O(1)$。
将链表中的网络结构保存到network结构体 首先来看看network结构体的定义,在include/darknet.h中: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 typedef struct network { int n; int batch; uint64_t *seen; int *t; float epoch; int subdivisions; layer *layers; float *output; learning_rate_policy policy; int benchmark_layers; float learning_rate; float learning_rate_min; float learning_rate_max; int batches_per_cycle; int batches_cycle_mult; float momentum; float decay; float gamma; float scale; float power; int time_steps; int step; int max_batches; int num_boxes; int train_images_num; float *seq_scales; float *scales; int *steps; int num_steps; int burn_in; int cudnn_half; int adam; float B1; float B2; float eps; int inputs; int outputs; int truths; int notruth; int h, w, c; int max_crop; int min_crop; float max_ratio; float min_ratio; int center; int flip; int blur; int mixup; float label_smooth_eps; int resize_step; int letter_box; float angle; float aspect; float exposure; float saturation; float hue; int random; int track; int augment_speed; int sequential_subdivisions; int init_sequential_subdivisions; int current_subdivision; int try_fix_nan; int gpu_index; tree *hierarchy; float *input; float *truth; float *delta; float *workspace; int train; int index; float *cost; float clip; #ifdef GPU float *delta_gpu; float *output_gpu; float *input_state_gpu; float *input_pinned_cpu; int input_pinned_cpu_flag; float **input_gpu; float **truth_gpu; float **input16_gpu; float **output16_gpu; size_t *max_input16_size; size_t *max_output16_size; int wait_stream; float *global_delta_gpu; float *state_delta_gpu; size_t max_delta_gpu_size; #endif int optimized_memory; size_t workspace_size_limit; } network;
为network结构体分配内存空间,函数定义在src/network.c文件中,代码如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 network make_network (int n) network net = {0 }; net.n = n; net.layers = (layer*)xcalloc (net.n, sizeof net.seen = (uint64_t *)xcalloc (1 , sizeof uint64_t )); #ifdef GPU net.input_gpu = (float **)xcalloc (1 , sizeof float *)); net.truth_gpu = (float **)xcalloc (1 , sizeof float *)); net.input16_gpu = (float **)xcalloc (1 , sizeof float *)); net.output16_gpu = (float **)xcalloc (1 , sizeof float *)); net.max_input16_size = (size_t *)xcalloc (1 , sizeof size_t )); net.max_output16_size = (size_t *)xcalloc (1 , sizeof size_t )); #endif return net; }
在src/parser.c中的parse_network_cfg()函数中,从net变量开始,依次为其中的指针变量分配内存。由于第一个段[net]中存放的是和网络并不直接相关的配置参数, 因此网络层的数目为sections->size - 1,即:network *net = make_network(sections->size - 1);
将链表中的网络参数解析后保存到network结构体,配置文件的第一个段一定是[net]段,该段的参数解析由parse_net_options()函数完成,函数定义在src/parser.c中。之后的各段都是网络中的层。比如完成特定特征提取的卷积层,用来降低训练误差的shortcur层和防止过拟合的dropout层等。这些层都有特定的解析函数:比如parse_convolutional(), parse_shortcut()和parse_dropout()。每个解析函数返回一个填充好的层l,将这些层全部添加到network结构体的layers数组中。即是:net->layers[count] = l;另外需要注意的是这行代码:if (l.workspace_size > workspace_size) workspace_size = l.workspace_size;,其中workspace代表网络的工作空间,指的是所有层中占用运算空间最大那个层的workspace。因为在CPU或GPU中某个时刻只有一个层在做前向或反向传播。输出层只能在网络搭建完毕之后才可以确定,输入层需要考虑batch_size的因素,truth是输入标签,同样需要考虑batch_size的因素。具体层的参数解析后面专门写一篇推文来帮助理解。
到这里,网络的宏观解析结束。parse_network_cfg()(src/parser.c中)函数返回解析好的network类型的指针变量。
为啥需要中间数据结构缓存? 这里可能有个疑问,为什么不将配置文件读取并解析到network结构体变量中, 而要使用一个中间数据结构来缓存读取到的文件呢?因为,如果不使用中间数据结构来缓存. 将读取和解析流程串行进行的话, 如果配置文件较为复杂, 就会长时间使文件处于打开状态。如果此时用户更改了配置文件中的一些条目, 就会导致读取和解析过程出现问题。分开两步进行可以先快速读取文件信息到内存中组织好的结构中, 这时就可以关闭文件. 然后再慢慢的解析参数。这种机制类似于操作系统中断的底半部机制, 先处理重要的中断信号, 然后在系统负荷较小时再处理中断信号中携带的任务。