AlexeyAB版Darknet使用教程
前言
自从Joseph Redmon提出了yolov3后,其darknet仓库已经获得了16k的star,足以说明darknet的流行。该作者最新一次更新也是一年前了,没有继续维护。不过自来自俄国的大神AlexeyAB在不断地更新darknet, 不仅添加了darknet在window下的适配,而且实现了多种SOTA目标检测算法。AlexeyAB也在库中提供了一份详细的建议,从编译、配置、涉及网络到测量指标等,一应俱全。通过阅读和理解AlexeyAB的建议,可以为我们带来很多启发。本文是来自翻译AlexeyAB的darknet中的README。
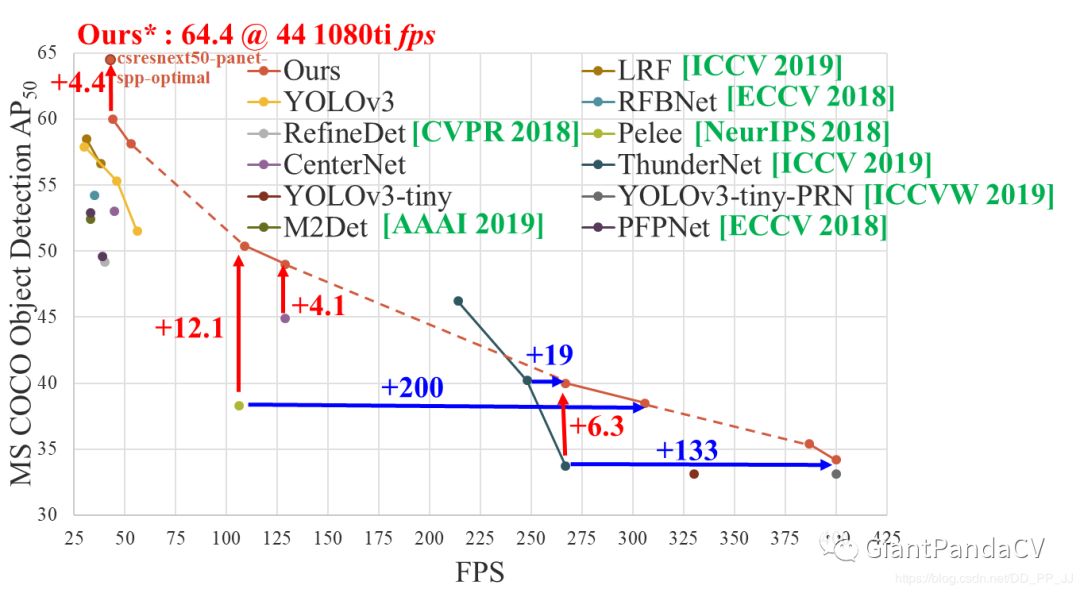
下图是CSPNet中统计的目前的State of the Art的目标检测模型。其中csresnext50-panet-spp-optimal模型是CSPNet中提出来的,结合AlexeyAB版本的Darknet就可以实现。
1. 依赖
1.1 环境要求
- window系统或者linux系统。
- CMake版本高于3.8。
- CUDA 10.0,cuDNN>=7.0。
- OpenCV版本高于2.4。
- Linux下需要GCC 或者Clang, Window下需要Visual Studio 15、17或19版。
1.2 数据集获取
- MS COCO数据集: 使用
./scripits/get_coco_dataset.sh来获取数据集。 - OpenImages数据集: 使用
./scripits/get_openimages_dataset.py获取数据集,并按照规定的格式重排训练集。 - Pascal VOC数据集: 使用
./scripits/voc_label.py对数据集标注进行处理。 - ILSVRC2012数据集(ImageNet Classification): 使用
./scripits/get_imagenet_train.sh获取数据集,运行./scripits/imagenet_label.sh用于验证集。 - German/Belgium/Russian/LISA/MASTIF 交通标志数据集。
- 其他数据集,请访问
https://github.com/AlexeyAB/darknet/tree/master/scripts#datasets
结果示意:

其他测试结果可以访问:https://www.youtube.com/user/pjreddie/videos
2. 相比原作者Darknet的改进
- 添加了对windows下运行darknet的支持。
- 添加了SOTA模型: CSPNet, PRN, EfficientNet。
- 在官方Darknet的基础上添加了新的层:[conv_lstm], [scale_channels] SE/ASFF/BiFPN, [local_avgpool], [sam], [Gaussian_yolo], [reorg3d] (修复 [reorg]), 修复 [batchnorm]。
- 可以使用
[conv_lstm]层或者[crnn]层来实现针对视频的目标检测。 - 添加了多种数据增强策略:
[net] mixup=1 cutmix=1 mosaic=1 blur=1。 - 添加了多种激活函数: SWISH, MISH, NORM_CHAN, NORM\CHAN_SOFTMAX。
- 增加了使用CPU-RAM提高GPU处理训练的能力,以增加
mini_batch_size和准确性。 - 提升了二值网络,让其在CPU和GPU上的训练和测试速度变为原来的2-4倍。
- 通过将Convolutional层和Batch-Norm层合并成一个层,提升了约7%速度。
- 如果在Makefile中使用CUDNN_HALF参数,可以让网络在TeslaV100,GeForce RTX等型号的GPU上的检测速度提升两倍。
- 针对视频的检测进行了优化,对高清视频检测速度可以提升1.2倍,对4k的视频检测速度可以提升2倍。
- 数据增强部分使用Opencv SSE/AVX指令优化了原来朴素实现的数据增强,数据增强速度提升为原来的3.5倍。
- 在CPU上使用AVX指令来提高了检测速度,yolov3提高了约85%。
- 在网络多尺度训练(
random=1)的时候优化了内存分配。 - 优化了检测时的GPU初始化策略,在bacth=1的时候执行初始化而不是当batch=1的时候重新初始化。
- 添加了计算mAP,F1,IoU, Precision-Recall等指标的方法,只需要运行
darknet detector map命令即可。 - 支持在训练的过程中画loss曲线和准确率曲线,只需要添加
-map标志即可。 - 提供了
-json_port,-mjpeg_port选项,支持作为json和mjpeg 服务器来在线获取的结果。可以使用你的编写的软件或者web浏览器与json和mjpeg服务器连接。 - 添加了Anchor的计算功能,可以根据数据集来聚类得到合适的Anchor。
- 添加了一些目标检测和目标跟踪的示例:
https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp - 在使用错误的cfg文件或者数据集的时候,添加了运行时的建议和警告。
- 其它一些代码修复。
3. 命令行使用
Linux中使用./darknet,window下使用darknet.exe.
Linux中命令格式类似./darknet detector test ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights
Linux中的可执行文件在根目录下,Window下则在\build\darknet\x64文件夹中。以是不同情况下应该使用的命令:
- Yolo v3 COCO - 图片测试:
darknet.exe detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights -thresh 0.25 - 输出坐标 of objects:
darknet.exe detector test cfg/coco.data yolov3.cfg yolov3.weights -ext_output dog.jpg - Yolo v3 COCO - 视频测试:
darknet.exe detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights -ext_output test.mp4 - 网络摄像头:
darknet.exe detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights -c 0 - 网络视频摄像头 - Smart WebCam:
darknet.exe detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights http://192.168.0.80:8080/video?dummy=param.mjpg - Yolo v3 - 保存视频结果为res.avi:
darknet.exe detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights test.mp4 -out_filename res.avi - Yolo v3 Tiny版本 COCO - video:
darknet.exe detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights test.mp4 - JSON and MJPEG 服务器 :创建JSON和MJPEG服务器,允许软件或Web浏览器进行与服务器之间进行多个连接 。假设两者需要的端口为
ip-address:8070和8090:./darknet detector demo ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights test50.mp4 -json_port 8070 -mjpeg_port 8090 -ext_output - Yolo v3 Tiny on GPU:
darknet.exe detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights -i 1 test.mp4 - 另一个可进行图片测试的命令 Yolo v3 COCO - 图片测试:
darknet.exe detect cfg/yolov3.cfg yolov3.weights -i 0 -thresh 0.25 - 在 Amazon EC2上训练, 如果想要看mAP和Loss曲线,运行以下命令:
http://ec2-35-160-228-91.us-west-2.compute.amazonaws.com:8090(Darknet 必须使用OpenCV进行编译才能使用该功能):./darknet detector train cfg/coco.data yolov3.cfg darknet53.conv.74 -dont_show -mjpeg_port 8090 -map - 186 MB Yolo9000 - 图片分类:
darknet.exe detector test cfg/combine9k.data cfg/yolo9000.cfg yolo9000.weights - 处理一系列图片,并保存结果为json文件:
darknet.exe detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights -ext_output -dont_show -out result.json < data/train.txt - 处理一系列图片,并保存结果为txt文件:
darknet.exe detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights -dont_show -ext_output < data/train.txt > result.txt - 伪标注: 处理一个list的图片
data/new_train.txt,可以让结果保存为Yolo训练所需的格式,标注文件为.txt。通过这种方法可以迅速增加训练数据量。具体命令为:darknet.exe detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights -thresh 0.25 -dont_show -save_labels < data/new_train.txt - 如何计算anchor(通过聚类得到):
darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416 - 计算mAP@IoU=50:
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights - 计算mAP@IoU=75:
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights -iou_thresh 0.75
利用Video-Camera和Mjepg-Stream在Android智能设备中运行YOLOv3
下载 mjpeg-stream APP: IP Webcam / Smart WebCam:
- Smart WebCam - 从此处下载:
https://play.google.com/store/apps/details?id=com.acontech.android.SmartWebCam2 - IP Webcam下载地址:
https://play.google.com/store/apps/details?id=com.pas.webcam
- Smart WebCam - 从此处下载:
将你的手机与电脑通过WIFI或者USB相连。
开启手机中的Smart WebCam APP。
将以下IP地址替换,在Smart WebCam APP中显示,并运行以下命令:
Yolo v3 COCO-model: darknet.exe detector demo data/coco.data yolov3.cfg yolov3.weights http://192.168.0.80:8080/video?dummy=param.mjpg -i 0
4. Linux下如何编译Darknet
4.1 使用CMake编译Darknet
CMakeList.txt是一个尝试发现所有安装过的、可选的依赖项(比如CUDA,cuDNN, ZED)的配置文件,然后使用这些依赖项进行编译。它将创建一个共享库文件,这样就可以使用Darknet进行代码开发。
在克隆了项目库以后按照以下命令进行执行:
1 | mkdir build-release |
4.2 使用make编译Darknet
在克隆了项目库以后,直接运行make命令,需要注意的是Makefile中有一些可选参数:
- GPU=1代表编译完成后将可以使用CUDA来进行GPU加速(CUDA应该在
/usr/local/cuda中)。 - CUDNN=1代表通过cuDNN v5-v7进行编译,这样将可以加速使用GPU训练过程(cuDNN应该在
/usr/local/cudnn中)。 - CUDNN_HALF=1代表在编译的过程中是否添加Tensor Cores, 编译完成后将可以将目标检测速度提升为原来的3倍,训练网络的速度提高为原来的2倍。
- OPENCV=1代表编译的过程中加入OpenCV, 目前支持的OpenCV的版本有4.x/3.x/2.4.x, 编译结束后将允许Darknet对网络摄像头的视频流或者视频文件进行目标检测。
- DEBUG=1 代表是否开启YOLO的debug模式。
- OPENMP=1代表编译过程将引入openmp,编译结束后将代表可以使用多核CPU对yolo进行加速。
- LIBSO=1 代表编译库darknet.so。
- ZED_CAMERA=1 构建具有ZED-3D相机支持的库(应安装ZED SDK),然后运行。
5. 如何在Window下编译Darknet
5.1 使用CMake-GUI进行编译
建议使用以下方法来完成Window下Darknet的编译,需要环境有:Visual Studio 15/17/19, CUDA>10.0, cuDNN>7.0, OpenCV>2.4
使用CMake-GUI编译流程:
- Configure.
- Optional platform for generator (Set: x64) .
- Finish.
- Generate.
- Open Project.
- Set: x64 & Release.
- Build.
- Build solution.
5.2 使用vcpkg进行编译
如果你已经满足Visual Studio 15/17/19 、CUDA>10.0、 cuDNN>7.0、OpenCV>2.4的条件, 那么推荐使用通过CMake-GUI的方式进行编译。
否则按照以下步骤进行编译:
- 安装或更新Visual Studio到17+,确保已经对其进行全面修补。
- 安装CUDA和cuDNN。
- 安装Git和CMake, 并将它们加入环境变量中。
- 安装vcpkg然后尝试安装一个测试库来确认安装是正确的,比如:
vcpkg install opengl。 - 定义一个环境变量
VCPKG_ROOT, 指向vcpkg的安装路径。 - 定义另一个环境变量
VCPKG_DEFAULT_TRIPLET将其指向x64-windows。 - 打开Powershell然后运行以下命令:
1 | PS \> cd $env:VCPKG_ROOT |
- 打开Powershell, 切换到darknet文件夹,然后运行
.\build.ps1进行编译。如果要使用Visual Studio,将在Build后找到CMake为您创建的两个自定义解决方案,一个在build_win_debug中,另一个在build_win_release中,其中包含适用于系统的所有配置标志。
5.3 使用legacy way进行编译
如果你有CUDA10.0、cuDNN 7.4 和OpenCV 3.x , 那么打开
build\darknet\darknet.sln, 设置x64和Release 然后运行Build, 进行darknet的编译,将cuDNN加入环境变量中。- 在
C:\opencv_3.0\opencv\build\x64\vc14\bin找到opencv_world320.dll和opencv_ffmpeg320_64.dll, 然后将其复制到darknet.exe同级目录中。 - 在
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0中检查是否含有bin和include文件夹。如果没有这两个文件夹,那就将他们从CUDA安装的地方复制到这个地方。 - 安装cuDNN 7.4.1 来匹配CUDA 10.0, 将cuDNN添加到环境变量
CUDNN。将cudnn64_7.dll复制到\build\darknet\x64中。
- 在
如果你是用的是其他版本的CUDA(不是CUDA 10.0), 那么使用Notepad打开
build\darknet\darknet.vxcproj, 将其中的CUDA 10.0替换为你的CUDA的版本。然后打开\darknet.sln, 然后右击工程,点击属性properties, 选择CUDA C/C++, 然后选择Device , 然后移除compute_75,sm_75。之后从第一步从头开始执行。如果你没有GPU但是有OpenCV3.0, 那么打开
build\darknet\darknet_no_gpu.sln, 设置x64和Release, 然后运行build -> build darknet_no_gpu。如果你只安装了OpenCV 2.4.14,那你应该修改
\darknet.sln中的路径。- (右键点击工程) -> properties -> C/C++ -> General -> Additional Include Directories:
C:\opencv_2.4.13\opencv\build\include - (右键点击工程)-> properties -> Linker -> General -> Additional Library Directories:
C:\opencv_2.4.13\opencv\build\x64\vc14\lib
- (右键点击工程) -> properties -> C/C++ -> General -> Additional Include Directories:
如果你的GPU有Tensor Cores(Nvidia Titan V/ Tesla V100/ DGX-2等型号), 可以提升目标检测模型测试速度为原来的3倍,训练速度变为原来的2倍。
\darknet.sln-> (右键点击工程) -> properties -> C/C++ -> Preprocessor -> Preprocessor Definitions, and add here:CUDNN_HALF;注意:CUDA 必须在Visual Studio安装后再安装。
6. 如何训练
6.1 Pascal VOC dataset
下载预训练模型 (154 MB):
http://pjreddie.com/media/files/darknet53.conv.74将其放在build\darknet\x64文件夹中。下载pascal voc数据集并解压到
build\darknet\x64\data\voc放在build\darknet\x64\data\voc\VOCdevkit\文件夹中:2.1 下载
voc_label.py到build\darknet\x64\data\voc,地址为:http://pjreddie.com/media/files/voc_label.py。http://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar。http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar。http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar。
下载并安装python:
https://www.python.org/ftp/python/3.5.2/python-3.5.2-amd64.exe运行命令:
python build\darknet\x64\data\voc\voc_label.py(来生成文件: 2007_test.txt, 2007_train.txt, 2007_val.txt, 2012_train.txt, 2012_val.txt)。运行命令:
type 2007_train.txt 2007_val.txt 2012_*.txt > train.txt。在
yolov3-voc.cfg文件中设置batch=64和subdivisions=8。使用
train_voc.cmd或者使用以下命令开始训练:darknet.exe detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74。
(Note: 如果想要停止loss显示,添加 -dont_show标志. 如果使用CPU运行, 用darknet_no_gpu.exe 代替 darknet.exe。)
如果想要改数据集路径的话,请修改 build\darknet\cfg\voc.data文件。
Note: 在训练中如果你看到avg为nan,那证明训练出错。但是如果在其他部分出现nan,这属于正常现象,训练过程是正常的。
6.2 如何使用多GPU训练?
- 首先在一个GPU中训练大概1000个轮次:
darknet.exe detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74。 - 然后停下来基于这个保存的模型
/backup/yolov3-voc_1000.weights使用多GPU (最多4个GPU):darknet.exe detector train cfg/voc.data cfg/yolov3-voc.cfg /backup/yolov3-voc_1000.weights -gpus 0,1,2,3。
在多GPU训练的时候,learning rate需要进行修改,比如单gpu使用0.001,那么多gpu应该使用0.001/GPUS。然后cfg文件中的burn_in参数和max_batches参数要设置为原来的GPUS倍。
6.3 训练自定义数据集(重点关注)
训练较早提出的Yolo系列算法如yolov2-voc.cfg, yolov2-tiny-voc.cfg, yolo-voc.cfg, yolo-voc.2.0.cfg,请看https://github.com/AlexeyAB/darknet/tree/47c7af1cea5bbdedf1184963355e6418cb8b1b4f#how-to-train-pascal-voc-data。
Training Yolo v3:
- 创建与
yolov3.cfg内容相同的yolo-obj.cfg或者直接复制然后重命名为yolo-obj.cfg然后
设置
cfg文件中batch=64。设置
cfg文件中subdivisions=16。设置
cfg文件中max_batches参数 (一般可以设置为classes*2000但是不要低于4000), 比如 如果你有三个类,那么设置max_batches=6000。设置
steps参数,一般为80%和90%的max_batches。比如steps=4800,5400设置网络输入长宽必须能够整除32,比如
width=416 height=416`修改yolo层中的
classes=80改为你的类别的个数,比如classes=3:修改yolo层前一个卷积层convolutional输出通道数。修改的
filter个数有一定要求,按照公式filters=(classes+5)×3来设置。这里的5代表x, y, w, h, conf, 这里的3代表分配3个anchor。如果使用
[Gaussian_yolo](Gaussian_yolov3_BDD.cfg),filters计算方式不太一样,按照filters=(classes + 9)x3进行计算。通常来讲,filters的个数计算依赖于类别个数,坐标以及
mask的个数(cfg中的mask参数也就是anchors的个数)。举个例子,对于两个目标,你的
yolo-obj.cfg和yolov3.cfg不同的地方应该在每个[yolo]/[region]层的下面几行:
1 | [convolutional] |
- 在
build\darknet\x64\data\创建文件obj.names, 每行一个类别的名称。 - 在
build\darknet\x64\data\创建obj.data, 具体内容如下:
1 | classes= 2 # 你的类别的个数 |
- 将你的图片放在
build\darknet\x64\data\obj\文件夹下。 - 你应该标注你的数据集中的每一张图片,使用
Yolo_mark这个可视化GUI软件来标注出目标框并且产生标注文件。地址:https://github.com/AlexeyAB/Yolo_mark。
软件将会为每一个图像创建一个txt文件,并将其放在同一个文件夹中,命名与原图片的名称相同,唯一不同的就是后缀是txt。txt标注文件中每一个目标独占一行,按照<object-class> <x_center> <y_center> <width> <height>的格式排布。
具体参数解释:
<object-class>- 是从0到(classes-1)的整数,代表具体的类别。<x_center> <y_center> <width> <height>- 是归一化到(0.0 to 1.0]之间的浮点数,都是相对于图片整体的宽和高的一个相对值。比如:
<x> = <absolute_x> / <image_width>或者<height> = <absolute_height> / <image_height>需要注意的是:
<x_center> <y_center>- 是标注框的中心点,而不是左上角。请注意格式。举个例子,img1.txt中内容如下,代表有两个类别的三个目标:
1 | 1 0.716797 0.395833 0.216406 0.147222 |
- 在
build\darknet\x64\data\文件夹中创建train.txt文件,每行包含的是训练集图片的内容。其路径是相对于darknet.exe的路径或者绝对路径:
1 | data/obj/img1.jpg |
下载预训练权重,并将其放在
build\darknet\x64文件夹中。- 对于
csresnext50-panet-spp.cfg(133 MB):请查看原工程。 - 对于
yolov3.cfg, yolov3-spp.cfg(154 MB):请查看原工程。 - 对于
yolov3-tiny-prn.cfg , yolov3-tiny.cfg(6 MB):请查看原工程。 - 对于
enet-coco.cfg (EfficientNetB0-Yolov3):请查看原工程。
- 对于
使用以下命令行开始训练:
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74。对于linux用户使用以下命令开始训练:
./darknet detector train data/obj.data yolo-obj.cfg darknet53.conv.74(使用./darknet而不是darknet.exe)。如果想训练的过程中同步显示mAP(每四个epoch进行一次更新),运行命令:
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -map。- 权重文件
yolo-obj_last.weights将会保存在build\darknet\x64\backup\文件夹中,每100个迭代保存一次。 - 权重文件
yolo-obj_xxxx.weights将会保存在build\darknet\x64\backup\文件夹中,每1000个迭代保存一次。 - 如果不想在训练的过程中同步展示loss曲线,请执行以下命令
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -dont_show。 - 如果想在训练过程中查看mAP和Loss曲线,可以使用以下命令:
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -dont_show -mjpeg_port 8090 -map,然后在浏览器中打开 URLhttp://ip-address:8090。
- 权重文件
训练结束以后,将会在文件夹
build\darknet\x64\backup\中得到权重文件yolo-obj_final.weights。
- 在100次迭代以后,你可以停下来,然后从这个点加载模型继续训练。比如说, 你在2000次迭代以后停止训练,如果你之后想要恢复训练,只需要运行命令:
darknet.exe detector train data/obj.data yolo-obj.cfg backup\yolo-obj_2000.weights,而不需要重头开始训练。
注意:
- 如果在训练的过程中,发现
avg指标变为nan,那证明训练过程有误,可能是数据标注越界导致的问题。但是其他指标有nan是正常的。 - 修改
width,height的时候必须要保证两者都能够被32整除。 - 训练结束后,可以使用以下命令来进行测试:
darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights - 如果出现
Ouf of memery问题,那说明显卡的显存不够,你可以通过设置subdivisions参数,将其从原来的16提高为32或者64,这样就能降低使用的显存,保证程序正常运行。
6.4 训练tiny-yolo
训练tiny yolo与以上的训练过程并无明显区别,除了以下几点:
- 下载tiny yolo的预训练权重:
https://pjreddie.com/media/files/yolov3-tiny.weights - 使用以下命令行来获取预训练权重:
darknet.exe partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15, 这里的15代表前15个层,也就是backbone所在的层。 - 使用的配置文件应该是
cfg/yolov3-tiny_obj.cfg而不是yolov3.cfg - 使用以下命令开始训练:
darknet.exe detector train data/obj.data yolov3-tiny-obj.cfg yolov3-tiny.conv.15
如果想使用其他backbone进行训练比如 DenseNet201-Yolo或者ResNet50-Yolo, 你可以在以下链接中找到:https://github.com/AlexeyAB/darknet/blob/master/build/darknet/x64/partial.cmd
如果你采用的是自己设计的backbone,那就无法进行迁移学习,backbone可以直接进行参数随机初始化。
6.5 什么时候停止训练
建议为每个类分配至少2000次迭代,但是整体迭代次数不应少于4000次。如果想要更加精准地定义什么时候该停止训练,需要使用以下方法:
- 训练过程中,你将会看到日志中有很多错误的度量指标,你需要在avg指标不再下降的时候停止训练,如下图所示:
Region Avg IOU: 0.798363, Class: 0.893232, Obj: 0.700808, No Obj: 0.004567, Avg Recall: 1.000000, count: 8 Region Avg IOU: 0.800677, Class: 0.892181, Obj: 0.701590, No Obj: 0.004574, Avg Recall: 1.000000, count: 8
9002: 0.211667, 0.60730 avg, 0.001000 rate, 3.868000 seconds, 576128 images Loaded: 0.000000 seconds
9002 - 代表当前的迭代次数。
0.60730 avg - average loss (error) - 这个指标是平均loss, 其越低越好。
在这个指标不再下降的时候就可以停止训练了。最终的值大概分布在0.05-3.0之间,小而简单的模型通常最终loss比较小,大而复杂的loss可能会比较大。
训练完成后,你就可以从 darknet\build\darknet\x64\backup 文件夹中取出比较靠后的几个weights文件,并对他们进行测试,选择最好的权重文件。
举个例子,你在9000次迭代后停止训练,但最好的权重可能是7000,8000,9000次的值。这种情况的出现是由于过拟合导致的。过拟合是由于过度学习训练集的分布,而降低了模型在测试集的泛化能力。
Early Stopping Point示意图:

为了得到在early stopping point处的权重:
2.1 首先,你的obj.data文件中应该含有valid=valid.txt一项,用于测试在验证集的准确率。如果你没有验证集图片,那就直接复制train.txt重命名为valid.txt。
2.2 假如你选择在9000次迭代后停止,那可以通过以下命令测试7000,8000,9000三个模型的相关指标。选择最高mAP或者最高IoU的模型最为最终模型。
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weightsdarknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_8000.weightsdarknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_9000.weights
或者你可以选择使用-map标志符来直接实时测试mAP值:
1 | darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74 -map |
然后你就能得到loss曲线和mAP曲线,mAP每4个epoch对验证集进行一次测试,并将结果显示在图中。
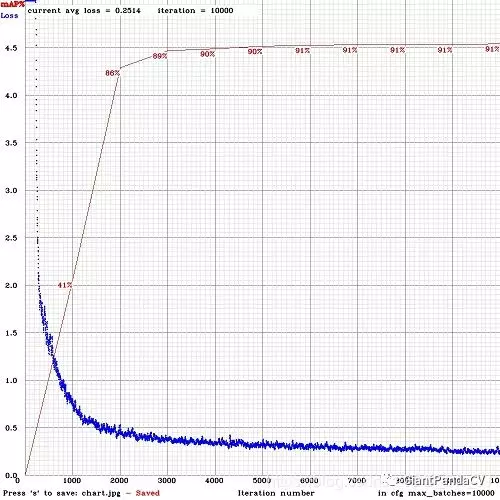
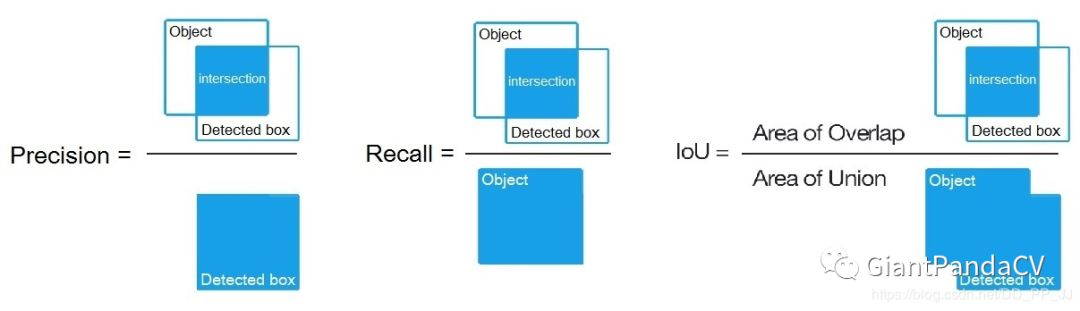
指标解释
IoU (intersect over union) - 平均交并比
mAP (mean average precision) - 每个类的平均精度。
mAP 是Pascal VOC竞赛的默认指标,与MS COCO竞赛中的AP50指标是一致的。
Precision和Recall参数在Pascal VOC竞赛中略微不同,但 IoU 的意义都是相同的。
6.6 如何在pascal voc2007数据集上计算mAP指标
- 在VOC2007中计算mAP:
- 下载VOC数据集,安装python并且下载
`2007_test.txt文件,具体可以参考链接:https://github.com/AlexeyAB/darknet#how-to-train-pascal-voc-data - 下载文件
https://raw.githubusercontent.com/AlexeyAB/darknet/master/scripts/voc_label_difficult.py到build\darknet\x64\data\文件夹,然后运行voc_label_difficult.py从而得到difficult_2007_test.txt。 - 将下面voc.data文件中的第四行#删除
1 | classes= 20 |
然后就有两个方法来计算得到mAP:
- 使用Darknet + Python: 运行
build/darknet/x64/calc_mAP_voc_py.cmd,你将得到yolo-voc.cfg模型的mAP值, mAP = 75.9% - 直接使用命令: 运行文件
build/darknet/x64/calc_mAP.cmd-你将得到yolo-voc.cfg模型, 得到mAP = 75.8%
YOLOv3的论文:https://arxiv.org/pdf/1612.08242v1.pdf指出对于416x416的YOLOv2,Pascal Voc上的mAP值是76.8%。我们得到的值较低,可能是由于模型在进行检测时的代码略有不同。
如果你想为tiny-yolo-voc计算mAP值,将脚本中tiny-yolo-voc.cfg取消注释,将yolo-voc.cfg注释掉。
如果你是用的是python 2.x 而不是python 3.x, 而且你选择使用Darknet+Python的方式来计算mAP, 那你应该使用 reval_voc.py 和 voc_eval.py 而不是使用 reval_voc_py3.py 和 voc_eval_py3.py 。以上脚本来自以下目录:https://github.com/AlexeyAB/darknet/tree/master/scripts。
目标检测的例子:darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights


7. 如何提升目标检测性能?
训练之前:
train_network_width * train_obj_width / train_image_width ~= detection_network_width * detection_obj_width / detection_image_widthtrain_network_height * train_obj_height / train_image_height ~= detection_network_height * detection_obj_height / detection_image_height完整模型(5个yolo层):
https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3_5l.cfg。Tiny模型(3个yolo层):
https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-tiny_3l.cfg。带空间金字塔池化的完整模型(3个yolo层):
https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-spp.cfg。在
cfg文件中将random设为1:这将在Yolo中使用多尺度训练,会提升检测模型准确率。在
cfg文件中把输入分辨率增大(height=608,width=608或者其他任意32的倍数):这将提升检测模型准确率。检查你要检测的每个目标在数据集中是否被标记,数据集中任何目标都不应该没有标签。在大多数训练出问题的情况中基本都是有错误的标签(通过使用某些转换脚本,使用第三方工具标注来获得标签),可以通过
https://github.com/AlexeyAB/Yolo_mark来检查你的数据集是否全部标注正确。我的损失函数很高并且mAP很低,训练出错了吗?在训练命令末端使用
-show_imgs标志来运行训练,你是否能看到有正确的边界预测框的目标(在窗口或者aug_...jpg)?如果没有,训练是发生错误了。对于你要检测的每个目标,训练数据集中必须至少有一个相似的目标,它们具有大致相同的形状,物体侧面姿态,相对大小,旋转角度,倾斜度,照明度等。理想的是,你的训练数据集包括具有不同比例,旋转角度,照明度,物体侧面姿态和处于不同背景的目标图像,你最好拥有2000张不同的图像,并且至少训练
2000×classes轮次。希望你的训练数据集图片包含你不想检测的未标注的目标,也即是无边界框的负样本图片(空的
.txt文件),并且负样本图片的数量和带有目标的正样本图片数量最好一样多。标注目标的最佳方法是:仅仅标记目标的可见部分或者标记目标的可见和重叠部分,或标记比整个目标多一点(有一点间隙)?根据你希望如何检测目标来进行标记。
为了对图片中包含大量目标的数据进行训练,添加
max=200或者更高的值在你cfg文件中yolo层或者region层的最后一行(YOLOv3可以检测到的目标全局最大数量为0,0615234375*(width*height)其中width和height是在cfg文件中的[net]部分指定的)。对于小目标的训练(把图像resize到416x416大小后小于16x16的目标):设置
layers = -1, 11而不是layers=-1, 36;设置stride=4而不是stride=2。对于既有大目标又有小目标的训练使用下面的模型:
如果你要训练模型将左右目标分为单独的类别(左/右手,左/右交通标志),那就禁用翻转的数据扩充方式,即在数据输入部分添加
flip=0。一般规则:你的训练数据集应包括一组您想要检测的相对大小的目标,如下:
即,对于测试集中的每个目标,训练集中必须至少有一个同类目标和它具有大约相同的尺寸:
object width in percent from Training dataset~=object width in percent from Test dataset也就是说,如果训练集中仅存在占图像比例80%-90%的目标,则训练后的目标检测网络将无法检测到占图像比例为1-10%的目标。
为了加快训练速度(同时会降低检测精度)使用微调而不是迁移学习,在[net]下面设置
stopbackward=1。然后执行下面的命令:./darknet partial cfg/yolov3.cfg yolov3.weights yolov3.conv.81 81这将会创建yolov3.conv.81文件,然后使用yolov3.conv.81文件进行训练而不是darknet53.conv.74。在观察目标的时候,从不同的方向、不同的照明情况、不同尺度、不同的转角和倾斜角度来看,对神经网络来说,它们都是不同的目标。因此,要检测的目标越多,应使用越复杂的网络模型。
为了让检测框更准,你可以在每个
yolo层添加下面三个参数ignore_thresh = .9 iou_normalizer=0.5 iou_loss=giou,这回提高map@0.9,但会降低map@0.5。当你是神经网络方面的专家时,可以重新计算相对于
width和height的anchors:darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416然后在3个[yolo]层放置这9个anchors。但是你需要修改每个[yolo]层的masks参数,让第一个[yolo]层的anchors尺寸大于60x60,第二个[yolo]层的anchors尺寸大于30x30,剩下就是第三个[yolo]层的mask。宁外,你需要修改每一个[yolo]层前面的filters=(classes + 5)x。如果很多计算的anchors都找不到合适的层,那还是使用Yolo的默认anchors吧。
训练之后:
- 没有必要重新训练模型,直接使用用
416x416分辨率训练出来的.weights模型文件。 - 但是要获得更高的准确率,你应该使用
608x608或者832x832来训练,注意如果Out of memory发生了,你应该在.cfg文件中增加subdivisions=16,32,64。 - 通过在
.cfg文件中设置(height=608andwidth=608)或者(height=832andwidth=832)或者任何32的倍数,这会提升准确率并使得对小目标的检测更加容易。
- 没有必要重新训练模型,直接使用用
8. 如何标注以及创建标注文件
下面的工程提供了用于标记目标边界框并为YOLO v2&v3 生成标注文件的带图像界面软件,地址为:https://github.com/AlexeyAB/Yolo_mark。
例如对于只有两类目标的数据集标注后有以下文件train.txt,obj.names,obj.data,yolo-obj.cfg,air 1-6.txt,bird 1-4.txt,接着配合train_obj.cmd就可以使用YOLO v2和YOLO v3来训练这个数据集了。
下面提供了5重常见的目标标注工具:
- C++实现的:
https://github.com/AlexeyAB/Yolo_mark - Python实现的:
https://github.com/tzutalin/labelImg - Python实现的:
https://github.com/Cartucho/OpenLabeling - C++实现的:
https://www.ccoderun.ca/darkmark/ - JavaScript实现的:
https://github.com/opencv/cvat
9. 使用YOLO9000
同时检测和分类9000个目标:darknet.exe detector test cfg/combine9k.data cfg/yolo9000.cfg yolo9000.weights data/dog.jpg
yolo9000.weights:186Mb的YOLO9000模型需要4G GPU显存,训练好的模型下载地址:http://pjreddie.com/media/files/yolo9000.weights。yolo9000.cfg:YOLO9000的c网络结构文件,同时这里也有9k.tree和coco9k.map文件的路径。1
2tree=data/9k.tree
map = data/coco9k.map9k.tree:9418个类别的单词数,每一行的形式为`,如果parent_id==-1那么这个标签没有父类别,地址为:https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/9k.tree`。coco9k.map:将MSCOCO的80个目标类别映射到9k.tree的文件,地址为:https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/coco9k.map。
combine9k.data:数据文件,分别是9k.labels。9k.names,inet9k.map的路径(修改combine9k.train.list文件的路径为你自己的)。地址为:https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/combine9k.data。9k.labels:9418类目标的标签。地址为:https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/9k.labels。9k.names:9418类目标的名字。地址为:https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/9k.names。inet9k.map:将ImageNet的200个目标类别映射到9k.tree的文件,地址为:https://raw.githubusercontent.com/AlexeyAB/darknet/master/build/darknet/x64/data/inet9k.map。
10. 如何将YOLO作为DLL和SO库进行使用?
在Linux上。
- 使用
build.sh或者 - 使用
cmake编译darknet或者 - 将
Makefile重的LIBSO=0改为LIBSO=1,然后执行make编译darknet
- 使用
在Windows上。
- 使用
build.ps1或者 - 使用
cmake编译darknet或者 - 使用
build\darknet\yolo_cpp_dll.sln或build\darknet\yolo_cpp_dll_no_gpu.sln解决方法编译darknet
- 使用
这里有两个API:
- 使用C++ API的C++例子:
https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp - 使用C API的Python例子:
https://github.com/AlexeyAB/darknet/blob/master/darknet.pyhttps://github.com/AlexeyAB/darknet/blob/master/darknet_video.py - C API:
https://github.com/AlexeyAB/darknet/blob/master/include/darknet.h - C++ API:
https://github.com/AlexeyAB/darknet/blob/master/include/yolo_v2_class.hpp
- 使用C++ API的C++例子:
11. 附录
为了将Yolo编译成C++的DLL文件
yolo_cpp_dll.dll:打开build\darknet\yolo_cpp_dll.sln解决方案,编译选项选X64和Release,然后执行Build->Build yolo_cpp_dll就,编译的一些前置条件为:- 安装CUDA 10.0。
- 为了使用cuDNN执行以下步骤:点击工程属性->properties->C++->Preprocessor->Preprocessor Definitions,然后在开头添加一行
CUDNN。
在自己的C++工程中将Yolo当成DLL文件使用:打开
build\darknet\yolo_console_dll.sln解决方案,编译选项选X64和Release,然后执行Build->Build yolo_console_dll:yolo_cpp_dll.dll-API:https://github.com/AlexeyAB/darknet/blob/master/include/yolo_v2_class.hpp- 你可以利用Windows资源管理器运行
build\darknet\x64\yolo_console_dll.exe可执行程序并使用下面的命令:yolo_console_dll.exe data/coco.names yolov3.cfg yolov3.weights test.mp4 - 启动控制台应用程序并输入图像文件名后,你将看到每个目标的信息:
- 如果要使用OpenCV-GUI你应该将
yolo_console_dll.cpp中的//#define OPENCV取消注释。 - 你可以看到视频检测例子的源代码,地址为yolo_console_dll.cpp的第75行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23struct bbox_t {
unsigned int x, y, w, h; // (x,y) - top-left corner, (w, h) - width & height of bounded box
float prob; // confidence - probability that the object was found correctly
unsigned int obj_id; // class of object - from range [0, classes-1]
unsigned int track_id; // tracking id for video (0 - untracked, 1 - inf - tracked object)
unsigned int frames_counter;// counter of frames on which the object was detected
};
class Detector {
public:
Detector(std::string cfg_filename, std::string weight_filename, int gpu_id = 0);
~Detector();
std::vector<bbox_t> detect(std::string image_filename, float thresh = 0.2, bool use_mean = false);
std::vector<bbox_t> detect(image_t img, float thresh = 0.2, bool use_mean = false);
static image_t load_image(std::string image_filename);
static void free_image(image_t m);
std::vector<bbox_t> detect(cv::Mat mat, float thresh = 0.2, bool use_mean = false);
std::shared_ptr<image_t> mat_to_image_resize(cv::Mat mat) const;
};
- 你可以利用Windows资源管理器运行
